![[컴퓨터 구조] Ch7. Microarchitecture](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fseu5s%2FbtrREVloSGW%2FMh70DQuaaLRklwwtBiTpMk%2Fimg.png)
Refrence : David Harris, Sarah Harris - Digital Design and Computer Architecture
Topics
- Performance Analysis
- Single-Cycle Processor
- Pipelined Processor
- Exceptions
- Advanced Microarchitecture
7.1 Introduction
Microarchitecture : 하드웨어에 architectrue를 구현
(1) Single-cycle : 각 명령어가 한 번에 single cycle로 실행
(2) Multicycle : 각 명령어들이 여러 cycle로 실행
(3) Pipelined : 각 명령어들이 여러 cycle로, 여러 개의 명령어들이 동시에 실행, 파이프라인으로 연결
Processor : (1) Datapath = functional blocks / (2) Control = control signals
7.2 Performance Analysis
Processor Performance
- 프로그램 실행 시간

- CPI : Cycles/instruction
- clock period : seconds/cycle
- IPC : instructions/cycle
- 문제점 : cost, power, performance
- Exercise 1

7.3 Single-Cycle Processor
Architectural State - processor의 현재 상태를 기억
- PC : 현재 수행 중인 명령어의 메모리 상 주소
- 32 registers
- Memory
Canonical Stage
Instruction Fetch stage ⇒ Decode stage ⇒ Excution stage ⇒ Memory stage ⇒ Write Back stage
명령어 인출 ⇒ 명령어 해석 ⇒ 명령어 실행 ⇒ 메모리 접근 ⇒ 결과 register에 저장
모든 종류의 프로세서가 공통으로 구현하는 stage
MIPS State Elements
Single-Cycle MIPS Processor : Datapath, Control
datapath 단계 → lw 명령어로 예시(5단계를 모두 거치는 명령어임)
Step 1: Fetch instruction

Instruction Fetch stage
Step 2: Read source operands from RF

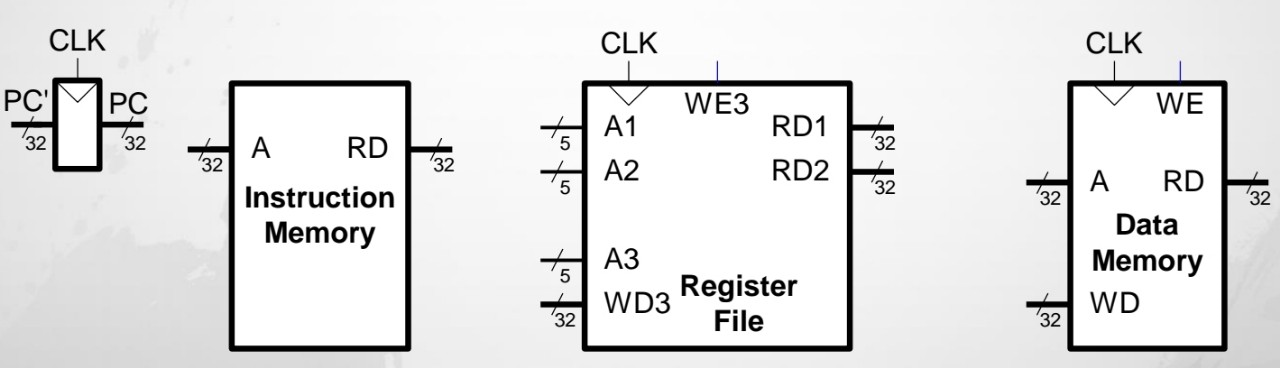
I type ⇒ op(6bit, 26~31) source(5bit, 21~25) destination(5bit, 16~20) immediate (16bit, 0~15)
⇒ 25:21번째 bit가 source operand이다!
Decode stage
Step 3: Sign-extend the immediate
15:0 번째 bit
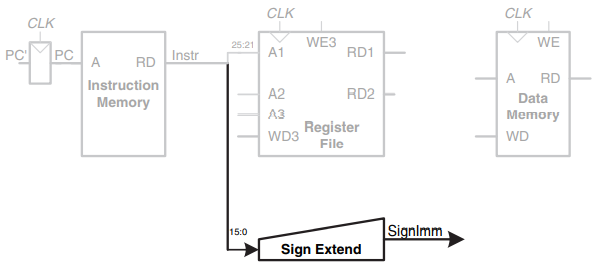
Step 4: Compute the memory address
base address와 offset을 더해서 메모리 주소를 구한다.
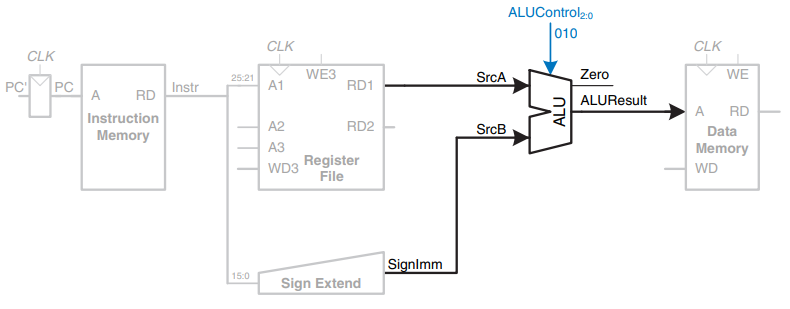
Excution stage
Step 5: Read data from memory and write it back to register file
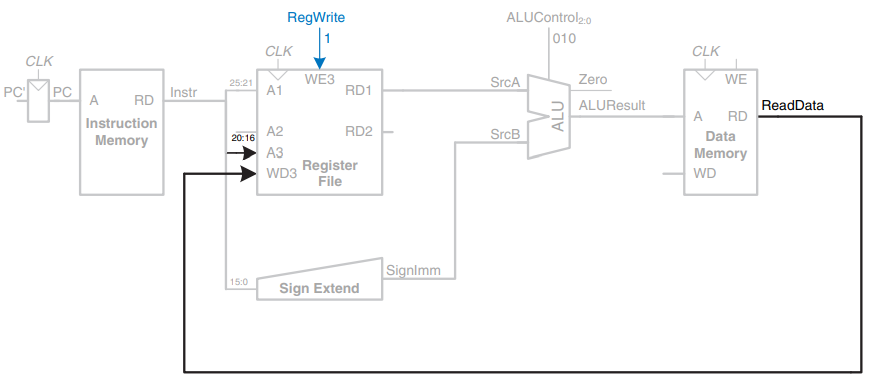
ALU의 연산 결과(메모리 주소)를 Data Memory의 input 으로 넣어 Memory에 저장 되어 있는 Data를 output으로 받아서 다시 Register에 써준다.
Memory stage → Write Back stage
Step 6: Determine address of next instruction
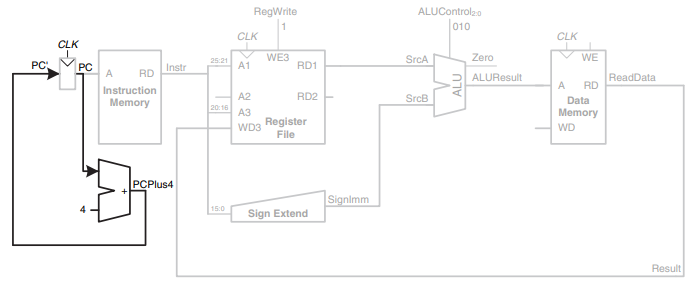
다음 명령어 수행을 위해 PC + 4
sw의 경우 ⇒ 저장할 위치 destination(writeData)도 읽어야 한다! 20:16 번째 bit
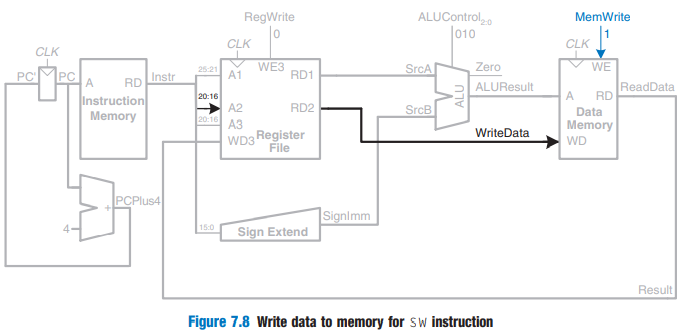
- Exercise 2PC의 주소에 따라서 0x00002000주소를 instruction memory에 input으로 넣는다.100011 / 01000(source) / 01001(destination) / 0000000000000000(immediate)
- OP코드로 보아 lw 명령어이다
- source : 01000 = 0x8
- destination : 01001 = 0x9
- immediate : 0x0

- OP코드 ⇒ sw
- source: 01000 = 0x8
- destination: 00100 = 0x9
- immediate = 0x4
- 101011 / 00100(source) / 01001(destination) / 00000000000000100(immediate)
- 다음 명령어 : PC + 4


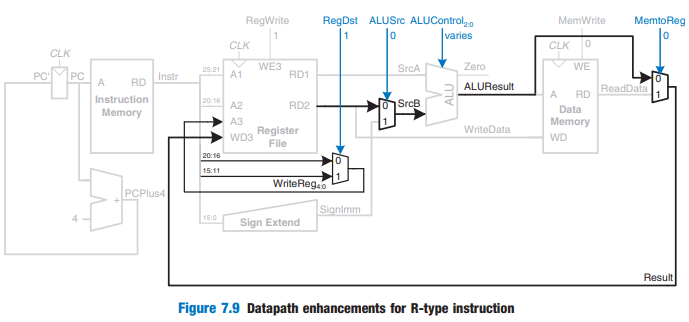
Single-Cycle Datapath : R-type
- rs, rt에서 read함
- ALU 결과를 register file에 write
- Write to rd
- RegDst = 1 / ALUSrc = 0 / MemtoReg = 0
- RegDst : R type일 때 1 / I type일 때 0
R type이냐 I type이냐에 따라서 읽어야 할 자리가 달라진다. 둘 다 rd
20:16[destinaion](I) VS 15:11[destination](R) ⇒ MUX와 RegDst 컨트롤 시그널에 의해서 결정한다!
- ALUSrc : R type일 때 0 → RD2를 ALU의 SrcB로 들어가게끔 한다
R type 명령어의 경우 다른 register도 source가 될 수 있기 때문에 MUX를 통해서 Immediate를 가져오는 I type과 구분 지어야 한다!
- MemtoReg : R type일 때 0 → 메모리를 건너 뛴다
R type의 경우 메모리를 건너뛰고 바로 register에 write back을 하기 위해 MUX가 위치한다.
- Exercise 3


Single-Cycle Datapath : beq
- rs에 있는 값과 rt에 있는 값이 같은지 비교
- branch target address, BTA = (sign-extended immediate << 2) + PC*4

Single-Cycle Processor : Control Unit
instruction을 받아서 OP 코드와 function 코드를 보고서 필요한 control 신호들을 생성해서 넣어준다
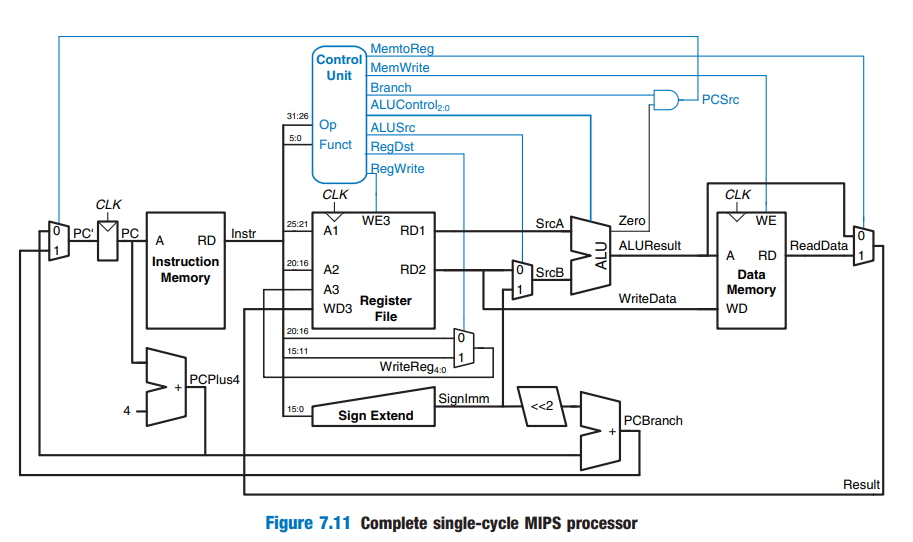
Single-Cycle Control
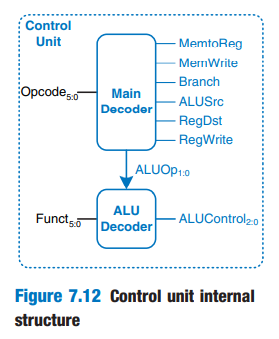
ALU review
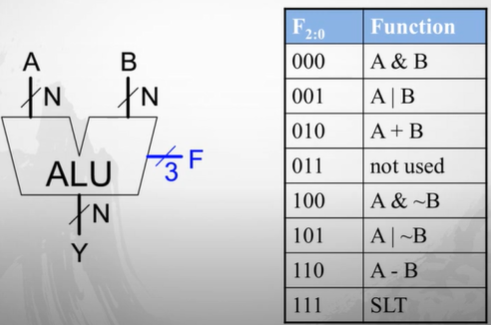
Control Unit : ALU Decoder
Main Decoder에서 ALUOP라는 신호를 만들고, ALU Decoder에서 이를 보고 Decoding한다
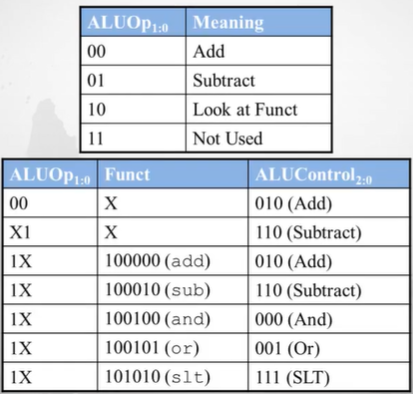
Control Unit : Main Decoder
- RegWrite : register file에 무언가를 write 하는가? 맞으면 1 / 아니면 0
- RegDst : R type이냐 I type이냐에 따라서 destination register 위치가 다름. R type=1 / I type= 0
- AluSrc : Alu의 source로 immediate가 들어가는가(1) / register가 들어가는가(0)
- Branch : branch instruction 이면 1 / 아니면 0
- MenWrite : memory에 write 하는가? 맞으면 1 / 아니면 0
- MemtoReg : RF에 write할 data가 memory에서 오는가(1) / ALU에서 오는가(0)
- ALUOp : Main decoder가 ALU decoder쪽으로 알려주는 신호
- Jump : 점프 instrcution인가?
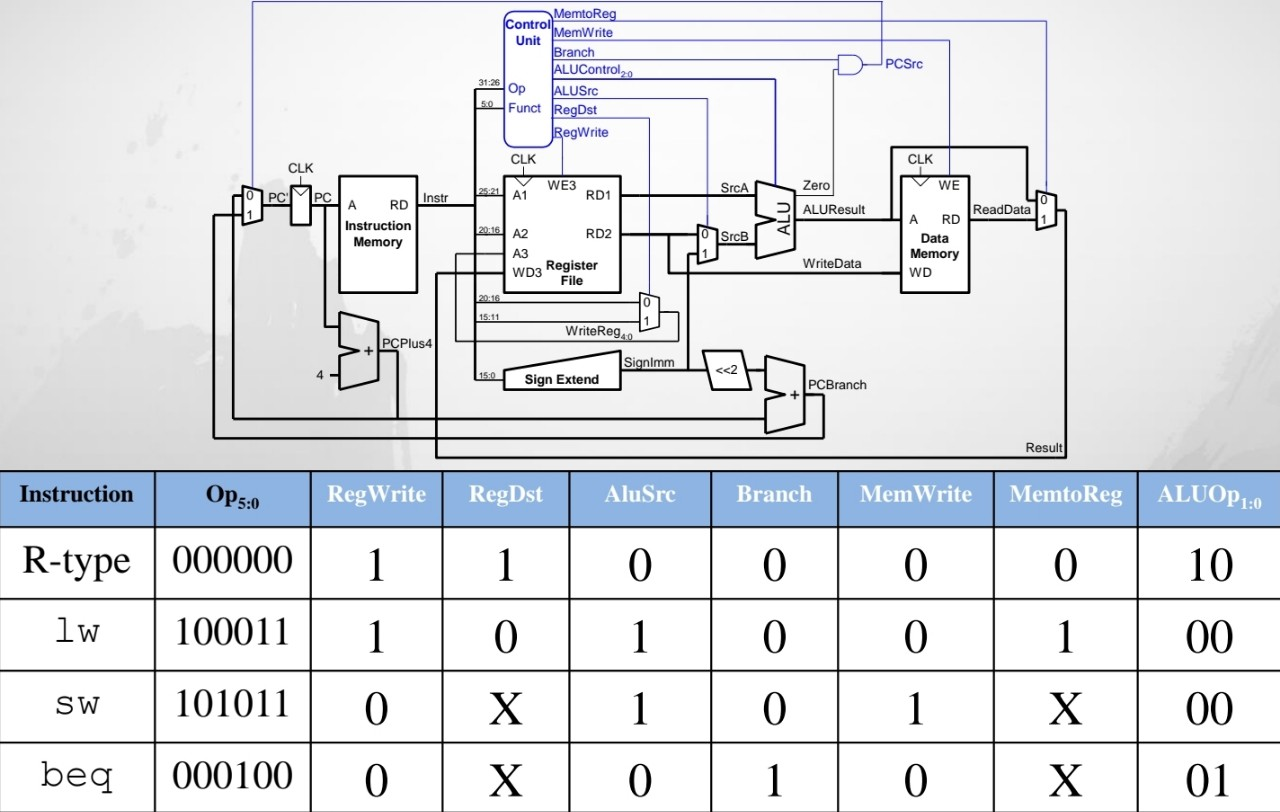
sw의 경우 Destination이 무엇이 되든지 상관 없으므로 Don’t care로 들어간다
마찬가지로 무엇이 되든지 상관없는 경우에는 Don’t care로 들어간다
Single-Cycle Datapath : or
파란 점선으로 표시된 것이 해당 instruction의 Data path이다.
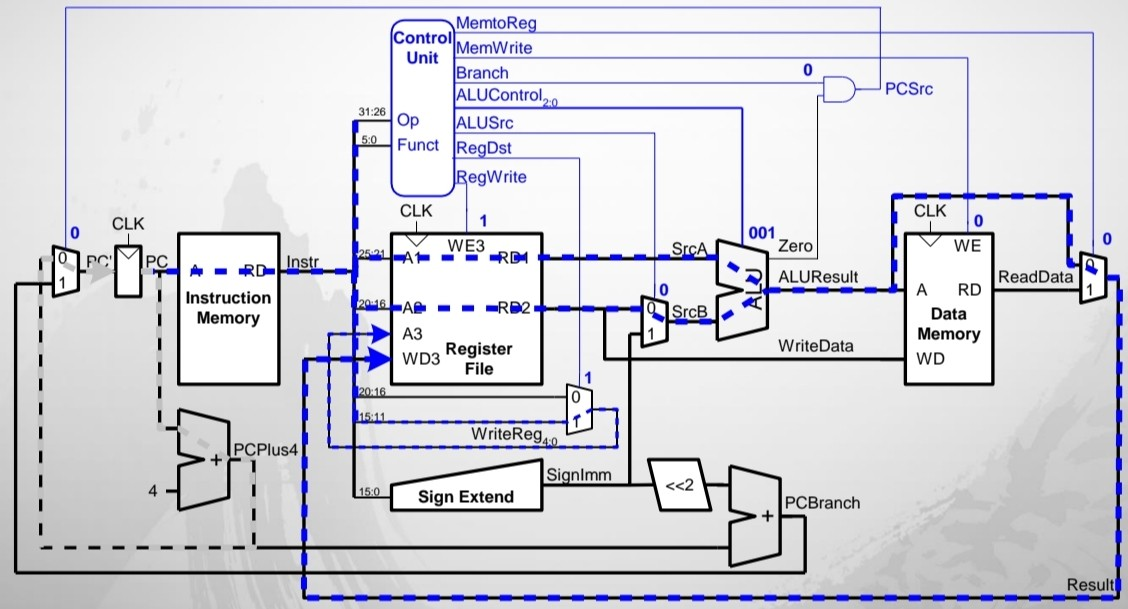
RegWrite : 1 / RegDst : 1 / ALUSrc : 0 / ALUControl : 001 (or에 해당) / Branch : 0 / Memwrite : 0 / MemtoReg : 0
+) Branch가 안 됐으니 다음 PC는 PC + 4 이다.
Single-Cycle Datapath : addi
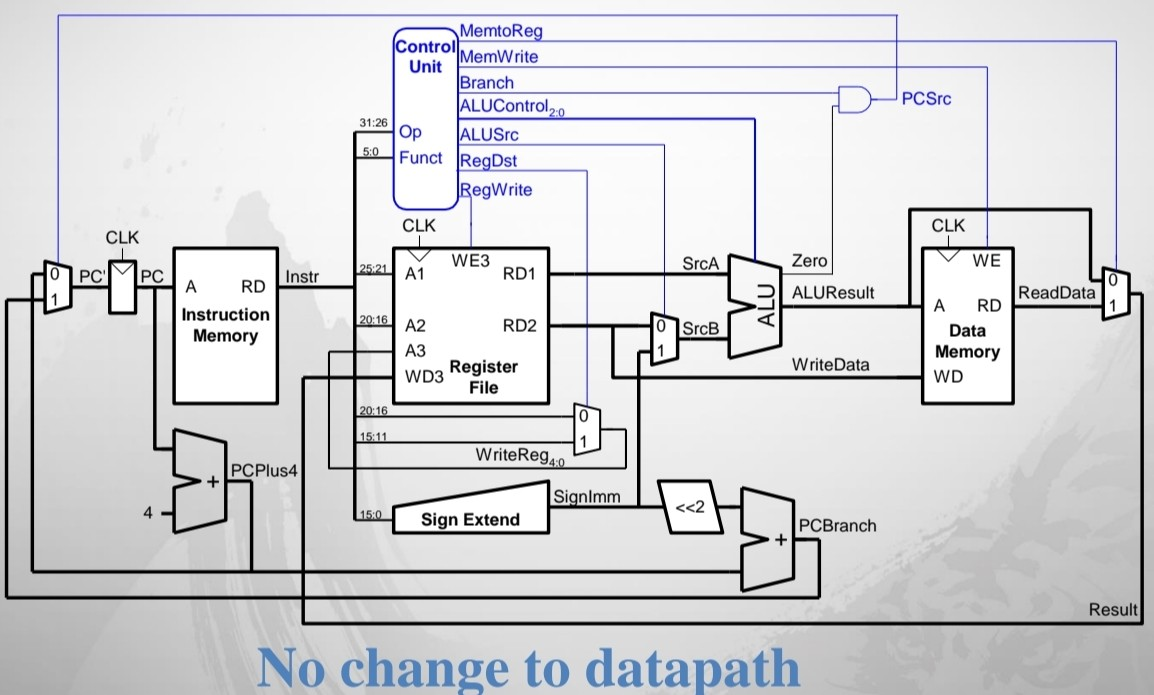
RegWrite : 1 / RegDst : 0 / ALUSrc : 1 (immediate를 선택) / ALUControl : add에 대한 값 / Branch : 0
/ MemWrite : 0 / MemtoReg : 0
⇒ Datapath를 변경하지 않아도 addi를 구현할 수 있다
Extended Functionality : j
25:0 bit에 곱하기 4를 한 값을 다음 PC로 해야 한다
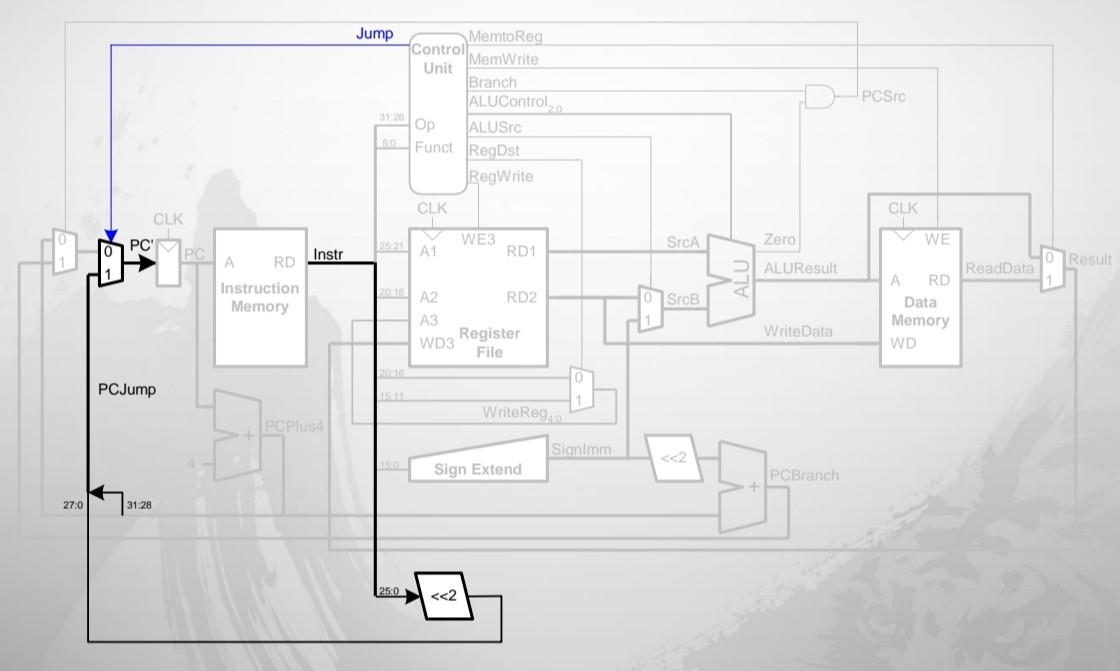
j = Op : 000100 / RegWrite : 0 / AluSrc : X / Branch : X / MemWrite : 0 / MemtoReg : X / ALUOp : XX / Jump : 1
Single-Cycle Performance
Program Execution Time = #instructions X CPI(1) X Tc
- critical path (가장 긴 path)

- Single-Cycle critical path :
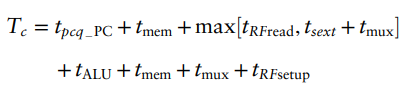
- Typically, limiting paths are : memory, ALU, register file //RFread가 큰 경우가 많다

- Exercise 1 : Program with 100 billion instructions 일 때 총 실행시간은?Execution time : (100 * 10^9)(1)(925 * 10^-12s) = 92.5s

7.5 Pipelined MIPS Processor
- Temporal parallelism
작업이 끝난 하드웨어를 놀게 하지 말고 미리 다음 instruction에 대해서 끊임없이 작업하도록 한다
→ 성능 최적화
- Fetch - Decode - Execute - Memory - Writeback
- Add pipelined registers between stages
- pipelined processor의 경우, 각 instruction에 대해서 각 작업이 모두 끝난 뒤에 동시에 다음 stage로 이동할 수 있다.
- 또한, 특정 stage가 필요 없는 instruction이더라도 무조건 5단계의 stage를 거쳐야 한다.
- 각 stage 끝난 후 그 값을 저장하는 register slice 존재
Single-Cycle VS Pipelined
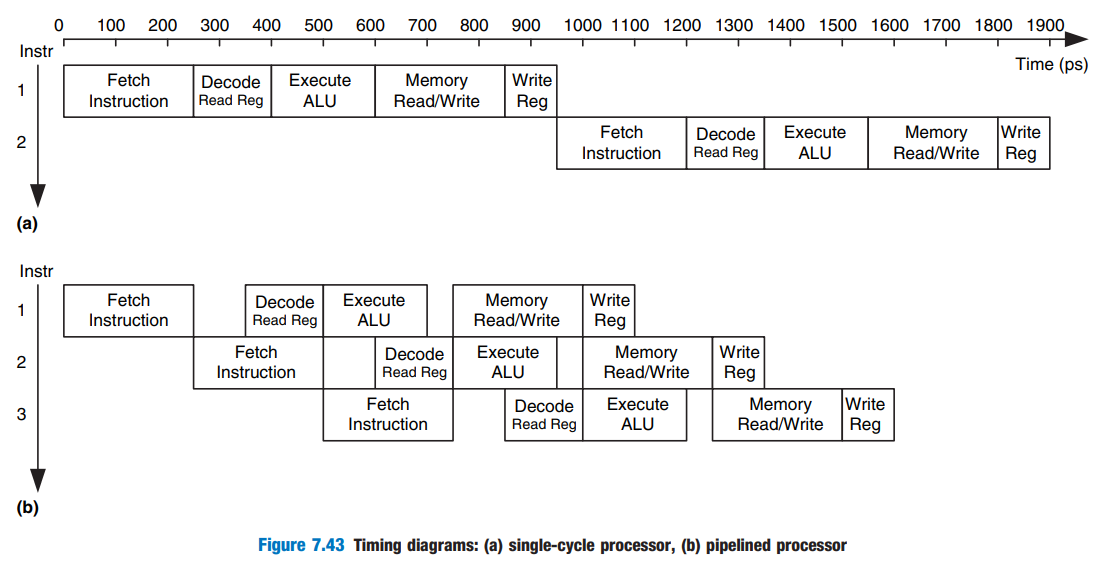
⇒ Pipelined processor의 하드웨어들은 작업이 끝나면 다음 instruction에 대해서 미리 작업하여 성능을 최적화 하였다.
⇒ 한 순간에 여러 개의 instrution에 대해서 동시에 작업하고 있다
⇒ latency 관점에서는 조금 느려졌지만, throughput 관점에서는 성능이 향상됨!
Pipelined Processor Abstraction
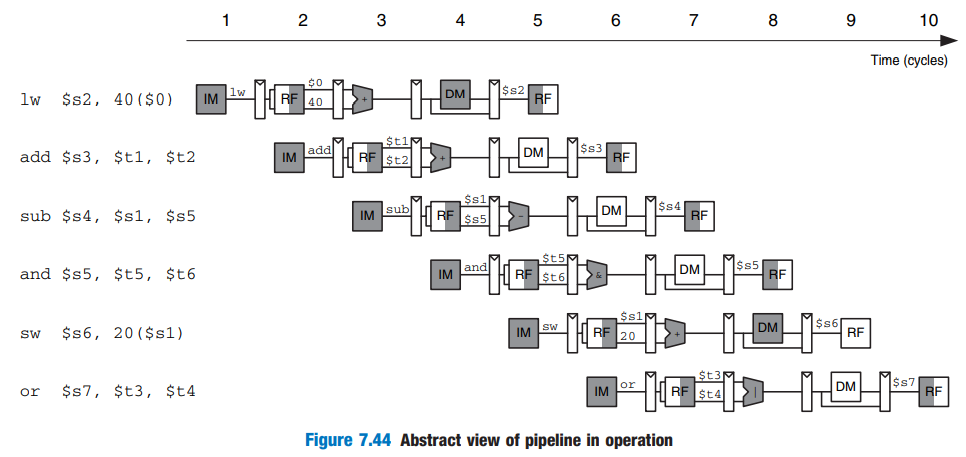
각 stage가 끝난 뒤에 그 결과를 임시로 저장하는 공간(register slice 사용)이 있다! (그림 상 긴 직사각형)
Single-Cycle & Pipelined Datapath
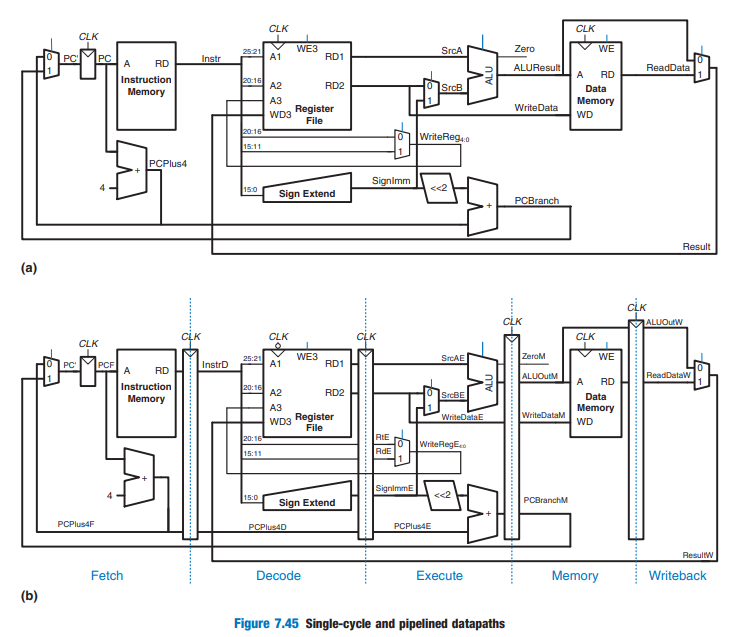
Corrected Pipelined Datapath
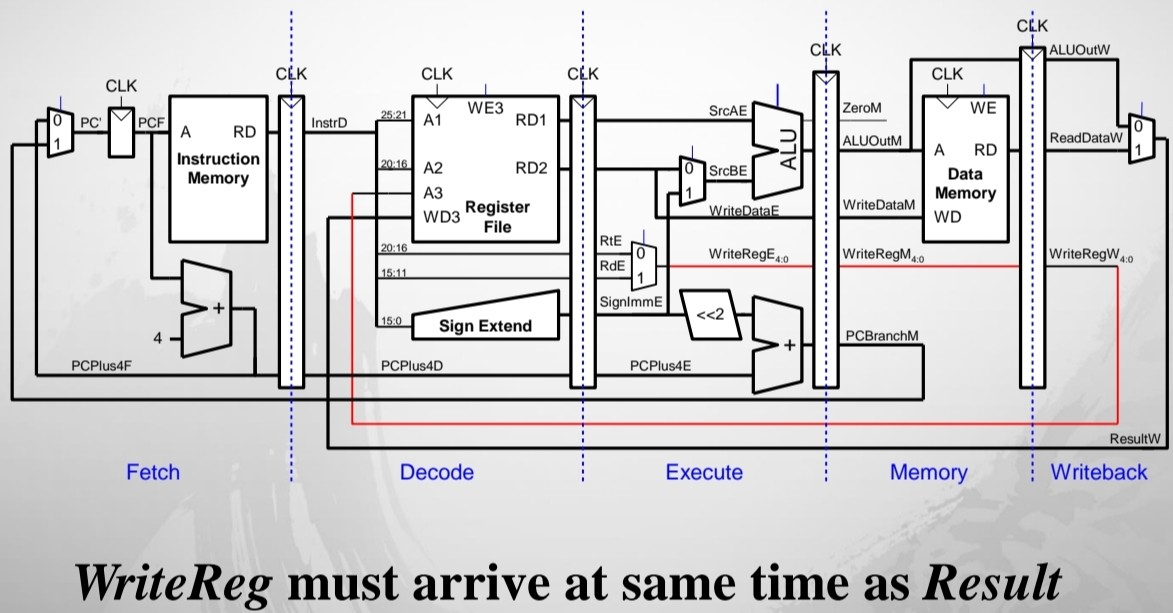
- WriteReg : Execute stage에서 계산하지만 Writeback stage에서 필요 ⇒ Writeback까지 전달
Pipelined Processor Control
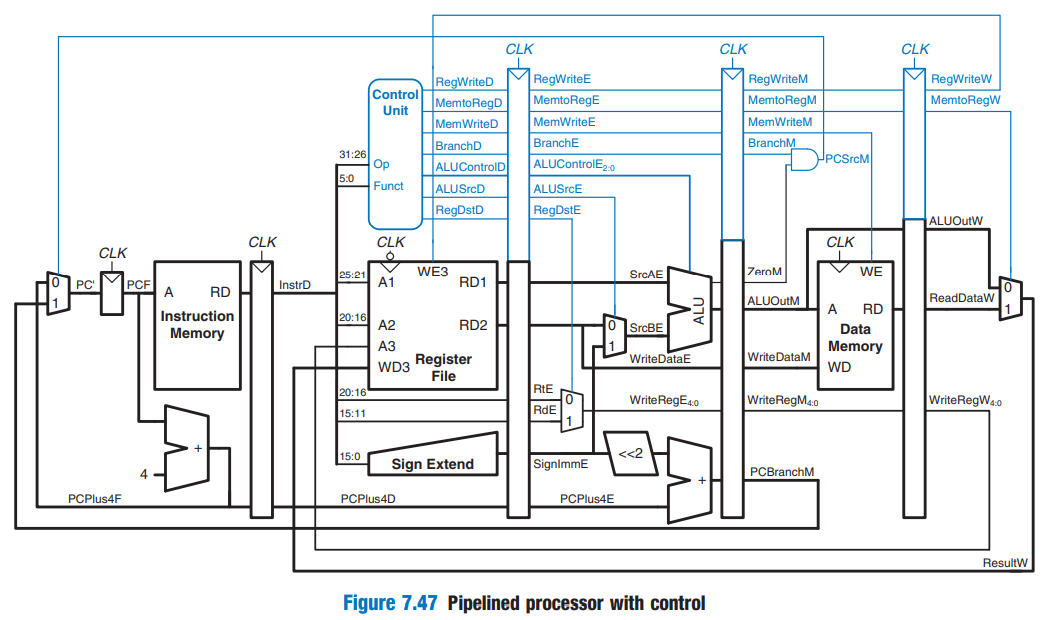
⇒ 모든 Control 신호들은 Decode stage에서 발생한다. but 모두가 decode stage에서 사용되는 것은 아니다. 따라서 각 신호들이 사용되는 stage까지 연장시킨다!
Pipeline Hazards
- 어느 instcution이 아직 완료되지 않은 instruction의 결과 값에 의존하는 경우
- Data hazard : RF에 write back 되기 전인 register value
- Control hazard : 다음 instruction이 아직 결정되지 않음
Data hazard
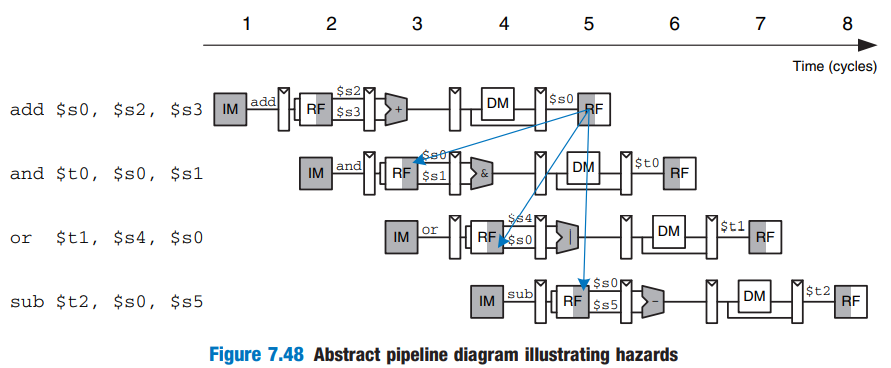
⇒ $s0 : 여러 instruction에서 읽는다! → pipelined processor에서 동시에 실행중인데?
Handling Data Hazards (해결책)
- complie 시 code를 재정렬한다.(ex:결과에 영향을 안 미치는 명령어를 사이에 넣도록 순서 변경)
- “nops” code를 complie time 때 삽입한다.add 명령어의 wirte back이 끝날 때까지 nop을 삽입한다. (2cycle동안)

- Forward data at the runtime⇒ add 명령어에서 execution stage를 지나면 아직 RF에 write back이 안 됐을 뿐, 이미 결과 값은 나온 상태이다. 따라서 계산 결과를 최대한 빨리 알 수 있을 때 다음 명령어로 넘겨주는 것.(1) Memory stage 시작할 때, execution stage 결과 값을 다음 명령어의 execution stage로 전달(3) RF에 업데이트가 되는 동시에 전달


- 조건
- MUX 추가하여 구분
- (2) Write back stage 시작할 때 전달
- ⇒ 굳이 RF에서 읽어오지 않고, 이전 명령어의 execution stage의 결과값을 읽어온다. (화살표)

하지만 모든게 해결되지는 않음.
lw의 경우 memory에서 데이터를 읽어오기 때문에 memory stage가 끝난 뒤에야 결과가 나온다.
⇒ data forwarding 을 해도 해결되지 않음
- Stalling : processor를 멈춰서 몇 cycle 동안 모든 명령어를 동일한 stage에 잠시 머물도록 하는 것⇒ 동일한 stage에 한 cycle만큼 더 머무름조건



- Exercise 1

Control Hazards
- beq : execution stage가 끝날 때까지 branch가 결정되지 않는다!!
⇒ memory stage까지 가봐야 다음 명령어가 무엇인지 알 수 있다.
⇒ 보통은 branch가 taken되지 않을 것을 가정하고 다음 명령어를 수행한다.
⇒ OR 기록을 보고 branch를 예상한다
- Branch misprediction penalty : 만약 아닐 시 기회 비용의 낭비
⇒ Figure 7.54에서, branch가 결국은 taken 되더라도 일단은 다음 명령어 3개를 수행하고, 그제서야 branch가 taken됨을 알아내고 그 쪽으로 jump한다. ⇒ 3 cycle의 패널티
Early Branch Resolution
- ALU를 사용하지 않고, Decode stage에서 바로 branch 결정을 내리는 것! ⇒ 추가적인 하드웨어
⇒ 성능 상 이득
구현
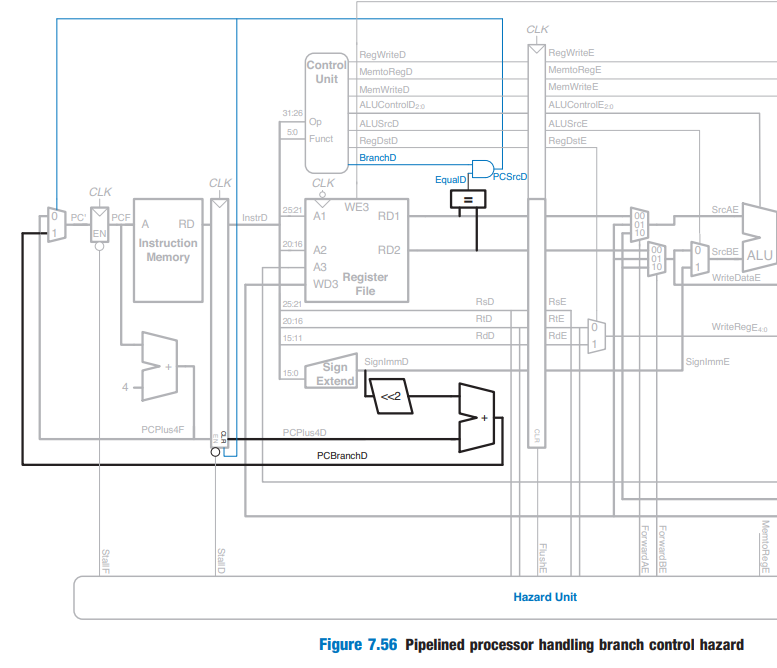
⇒ 하지만, 이로 인해 또다른 Data hazard가 발생한다. ⇒ MUX 추가
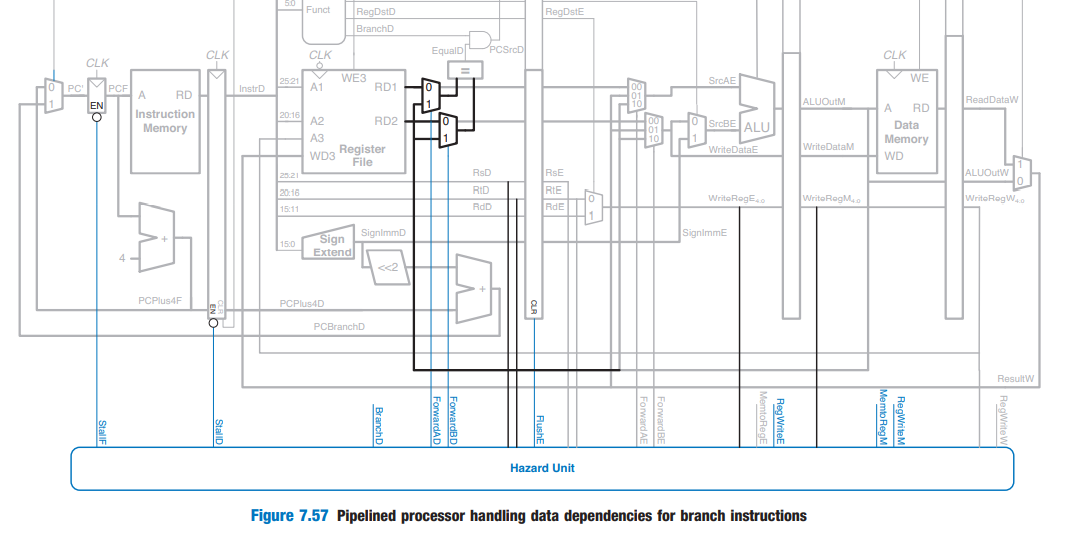
조건
- Exercise 2

Pipelined Performance Example
- CPI 계산

- Tc 계산 - 가장 긴 path 찾아서 계산
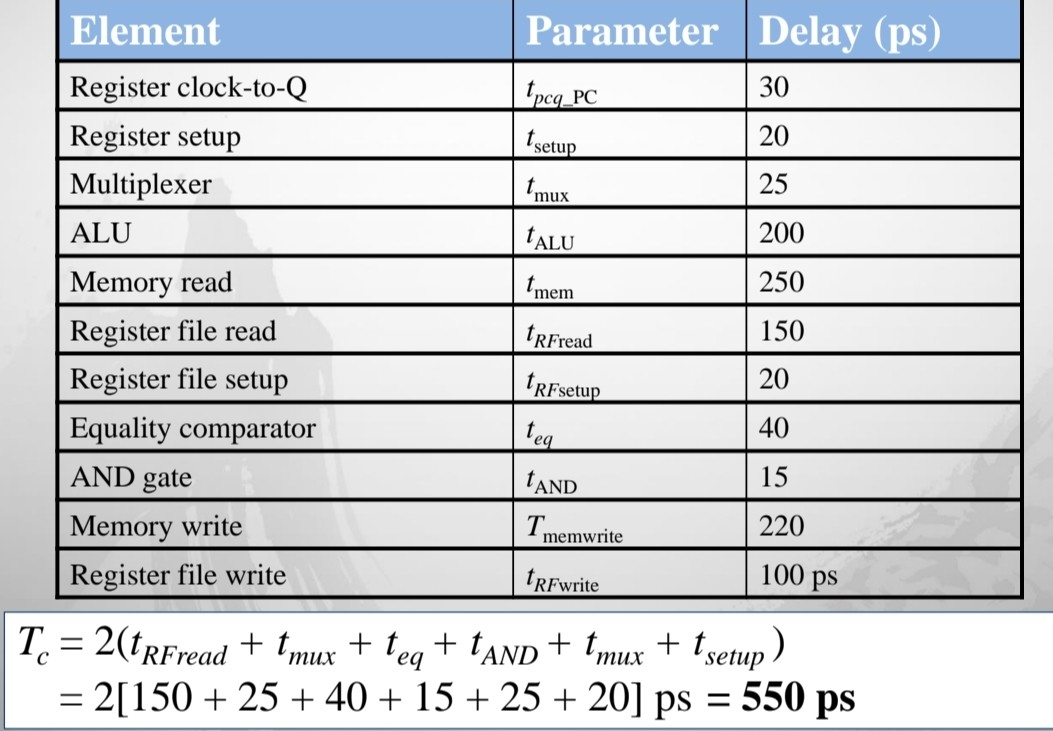
- Execution time = (100 * 10^9) * (1.15) * (550 * 10^-12) = 63 s
7.7 Exception
발생 요인
- interrupt : 하드웨어에 의해서
- trap : 소프트웨어에 의해서
Exception Registers
- 읽고 쓰기 위해서는 mfc0로 복사해서 사용 (mfc0 $t0, Cause)

- Cause : exception의 원인 저장

- EPC : exception 발생한 위치의 PC 저장
Exception Hardware : EPC & Cause
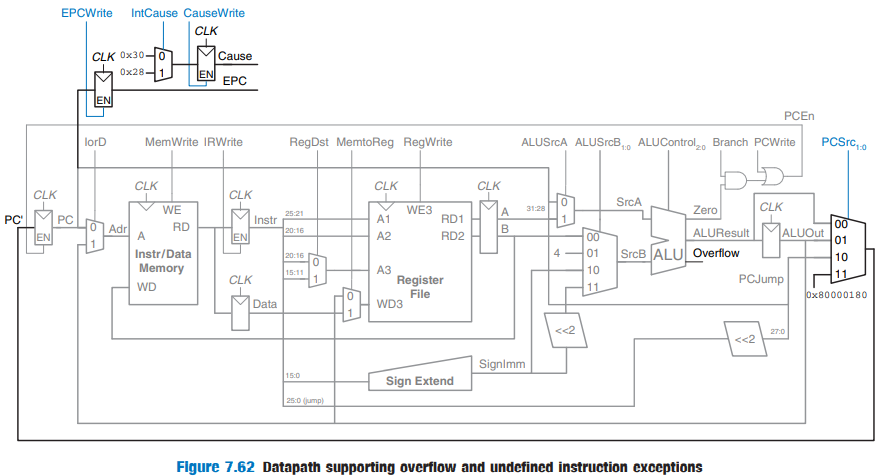
- PCSrc로 MUX 선택 → 0x80000180 주소로 jump
- → EPC에 저장
- IntCause을 통해서 Cause에 저장
Exception Hardware : mfc0
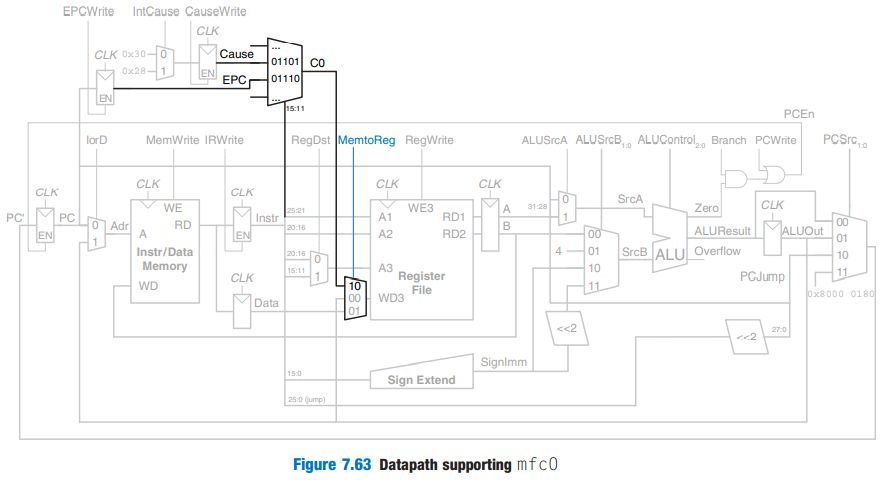
- 기존에 있었던 MUX에 입력값 10 추가 → MemtoReg 를 2bit로 확장
- 위쪽에 있는 MUX에서 Cause 나 EPC 중 하나를 고른 뒤 아래로 전달
'Computer Science > Computer Architecture' 카테고리의 다른 글
| [컴퓨터 구조] Ch8. Memory and I/O Systems(2) Virtual memory (0) | 2022.12.07 |
|---|---|
| [컴퓨터 구조] Ch8. Memory and I/O Systems(1) - Cache (0) | 2022.12.07 |
| [컴퓨터 구조] Ch6. Architecture (3) - Addressing Mode, Odds & Ends (0) | 2022.10.09 |
| [컴퓨터 구조] Ch6. Architecture (2) - Programming (0) | 2022.10.09 |
| [컴퓨터 구조] Ch6. Architecture (1) - Assembly Language, Machine Language (1) | 2022.10.08 |