![[데이터베이스] Chapter 19. Recovery System](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FJxhPy%2FbtrSUR5cDQm%2FzKoukfO0wAWEPRR4cHWx1k%2Fimg.png)
Reference
1. Database System Concepts-Abraham Silberschatz, Henry Korth, S. Sudarshan
2. Database System class by Professor Yon Dohn Chung, Department of Computer Science and Engineering, Korea University
중요한 내용 위주로 요약 & 정리하였습니다.
Topic
- Failure Classification
- Storage Structure
- Recovery and Atomicity
- Log-Based Recovery
- Checkpointing
19.1 Failure Classification
- Transaction failure : logical error, system error
- System crash : power failure, hardware or software failure
여기 까지는 data가 보존된다.
- Disk failure : disk의 손상으로 data가 손실된다.
19.2 Storage
자세한 내용은 ch12, 13을 정리한 글을 참고.
- volatile storage - system crash 시 data가 날아감 (memory)
- nonvolatile storage - system crash 시 data가 보존 (disk)
- stable storage - 모든 failure에 대해서 survive
stable storage를 구현하기 위해서는 여러 disk에 data를 복제해야 한다.
failure로 부터 복구하기 위해서는 모든 disk copy들을 비교하는 방법도 있지만 매우 비효율적이다. 대신, update하는 block들을 nonvolatile storage에 미리 기록하면 복구 시 이것들과만 비교하면 된다.
Data Access
memory에 올려야 data에 접근이 가능하다.
- physical blocks : disk에 존재하는 block들
- buffer blocks : main memory에 존재하는 block들
- input과 output은 block 단위로 이뤄진다.
- input(B): disk → buffer ↔ output(B): buffer → disk
각 트랜잭션은 private한 work-area가 있으며 여기에 접근하는 data의 local copy들이 있다.
- read(X): T의 work area → buffer ↔ write(X): buffer → T의 work area
- output(Bx)는 wirte(X)가 수행된 이후 곧바로 수행될 필요가 없다. (buffer manager가 관리)

19.3 Recovery and Atomicity
failure 발생해도 atomicity를 보장하기 위해서, database 자체를 수정하는 것이 아니라 stable storage에 우선 수정 사항을 기술해야 한다. ⇒ failure 발생 시 아직 commit되지 않은 트랜잭션은 지워서 atomicity를 보장한다
log-based recovery mechanisms
- update 행위를 log를 남겨서 미리 기록한다.
- 항상 연산 수행 전 log를 먼저 기록한다.
- log : log record의 sequence
- log는 stable storage에 보관된다.
- update 행위만 log를 남긴다. (read는 log X)
(1) <Ti start>
Ti이 write(X)를 수행하기 전 남기는 log
(2) <Ti, X, V1, V2>
Ti이 X에 대해서 V1→V2로 write 했을 때 남기는 log
(3) <Ti commit> / <Ti abort>
트랜잭션 종료
DB Modification via Buffer Manager
트랜잭션은 main memory내 work-area에서 연산을 수행
→ 트랜잭션은 write 를 통해 buffer block 데이터에 반영한다.
→ Buffer manager가 output을 통해 physical block에 반영한다.
이때, output은 전적으로 Buffer manager가 통제한다.
(1) immediate modification
- 트랜잭션이 commit되기 전에 DB의 modification도 허용
- 트랜잭션의 commit과 상관없이 언제든지 update된 block의 output이 가능
- output 순서는 write 순서로 진행
(2) deferred modification
- 트랜잭션이 commit될 때까지 대기 후 DB를 수정한다.
- uncommitted 트랜잭션의 log는 안 남는다.
Transaction Commit
- log record에 해당 트랜잭션의 commit log가 있어야만 그 트랜잭션이 commit됐다고 할 수 있다.
- log는 절대 지워지지 않고, 실제 발생한 순서대로 쌓인다.
- 트랜잭션이 commit 되었고 아직 output되지 않았다면, write의 결과는 여전히 buffer에 남아 있는 것이다.

Undo and Redo Operations
(1) undo
- failure 발생 당시 commit log가 없는 트랜잭션에 대해 실시
- 역순으로 <Ti start>가 나올 때까지 실시
- undo 행위도 log를 남긴다. (recover 도중 failure 발생을 대비)
- <Ti, X, old value>로 write를 undo
- 마지막은 <Ti abort>
(2) redo
- failure 발생 당시 commit log가 있는 트랜잭션에 대해 실시
- <Ti start>부터 실시
- log를 남기지 않는다.
- buffer manager가 output 했는지 확신할 수 없기 때문에 실시한다.
⇒ 이것을 검사하는 것보다는 overwrite하는 것이 더 효율적이다. ⇒ repeating history
example

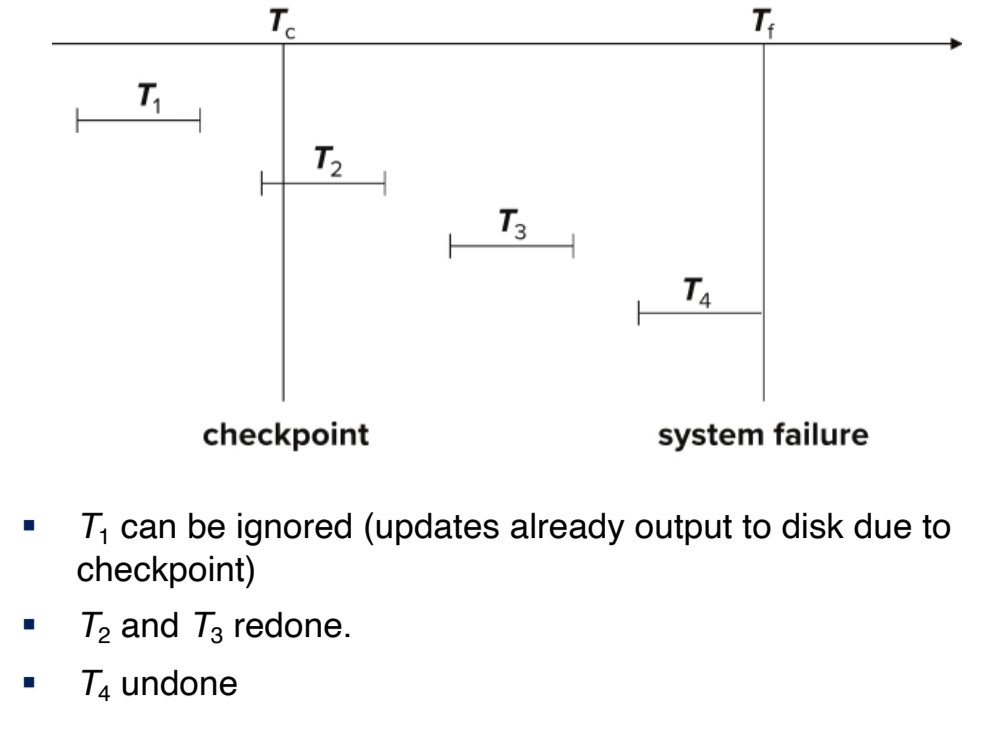
Checkpoints
recovery를 진행할 때, log에 있는 모든 트랜잭션을 redo/undo 하는 것은 매우 비효율적이다.
따라서 주기적으로 checkpointing 을 진행하여 <checkpoint L> 이전까지는 모든 modified buffer block들이 stable storage에 output 되었음을 보장한다.
- log가 쌓여서 너무 많은 redo를 실행하는 것을 방지하기 위해서 미리 checkpoint을 만들어서 그 지점 이하는 redo를 안 해도 되도록 보장한다.
- checkpointing을 진행하는 도중에는 모든 update가 중단된다.
Checkpoint Mechanism + 현재 실행 중인 T를 모두 stop
- main memory에 있는 모든 log record들을 우선 stable storage로 output한다.
- buffer block 중 수정되었던 block들은 모두 disk로 output한다.
- <checkpoint L> log record를 stable storage에 남긴다.
⇒ L 이전에 수행된 update 결과(drity block)에 대해 log buffer manager에게 모든 log record들을 stable storage로 옮기라고 요청 (log-force)
⇒ 이후 system failure가 일어나도, checkpoint 이후부터 redo 수행
Checkpoint를 사용한 recovery
- 가장 최근의 <checkpoint L> record를 찾는다.
- L 이후의 트랜잭션만 redo, undo의 대상이 된다.
- L 이전에 commit/abort 된 트랜잭션은 이미 stable storage에 update된 것이다.
- L ~ system failure 사이에 <Ti start>가 발견되면 Ti는 일단 undo 대상이다.
- <Ti commit>이 발견되면 Ti는 undo 대상에서 제외하고 redo 대상이 된다.
⇒ start: undo / commit: redo
⇒ redo phase에서 undo list 작성 후 undo phase에서 모두 undo
Example
19.4 Recovery Algorithm
(1) Logging (during normal operation)
- <Ti start> - 트랜잭션 시작
- <Ti, X, V1, V2> - X를 V2로 update
- <Ti commit> - 트랜잭션 끝
(2) Transaction rollbkack(during normal operation)
- 거꾸로 올라가면서 scan
- <Ti, X, V1, V2> 발견 → <Ti, X, V2> log 남기고 V2로 X를 wirte한다.
- <Ti start> 발견 → <Ti abort> log 남기고 scan을 멈춘다.
(3) Recovery from failure
- Redo phase: 모든 update 관련 트랜잭션을 redo한다. (committed, aborted, incomplete)
- Undo phase: 모든 incomplete 트랜잭션을 undo한다.
Redo phase
- checkpoint 앞까지 모든 T에 대해 redo실시
- <Ti, X, V1, V2> ⇒ redo (X를 V2로 write)
- 거꾸로 X, checkpoint 부터 순서대로 실시한다!
- redo는 log를 남기지 않는다.
- 동시에 undo list를 작성한다.
- <Ti start> ⇒ Ti를 undo list 에 추가
- <Ti commit> or <Ti abort> ⇒ Ti를 undo list 에서 제거
Undo phase
- undo list에 있는 T에 대해 undo 실시
- undo list가 빌 때까지 거꾸로 실시한다.
- undo log를 남긴다.
- <Ti, X, V1, V2> ⇒ undo (X를 V1로 write) + undo log 남기기
- <Ti start> ⇒ <Ti abort> log 남기기 + Ti를 undo list에서 제거
Example

19.5 Buffer Management
Log Record Buffering
- log는 위치가 연속적이며 시간순으로 buffer에 쌓인다.
- log record를 main memory의 buffer에 담아 두었다가 stable storage에 output한다.
- log buffer가 full
- log force operation 실행
- 트랜잭션이 commit될 때, 모든 log record들을 stable storage로 output한다.
- buffer manager에게 요청한다.
- Rule
- log record는 생성된 순서대로 output된다.
- <Ti commit>이라는 log record가 output되고 난 뒤에야 Ti는 commit 상태에 들어간다.
- write-ahead logging(WAL) : main memory의 buffer 내 block들이 stable storage로 output되기 전에, 해당 block의 관련된 모든 log record들이 먼저 stable storage로 output되어야 한다.
Database Buffering
- buffer가 꽉 찼는데 새로운 block이 필요하면, 기존 block 중 하나를 골라 buffer에서 지운다.
- 이때, 그 block이 update된 상태라면, stable storage에 output해줘야 한다.
이때 그 시점을 결정하는 policy가 다음과 같다.
Force = 트랜잭션이 commit된 시점에 바로 updated block을 disk로 output할 것인가?
Stral = 트랜잭션이 uncommitted 상태에서 updated block을 disk로 output할 것인가?
(1) Force policy
- 트랜잭션이 완료된 후(committed) 곧바로 데이터를 disk에 기록한다.
(2) No-force policy
- 트랜잭션이 완료된 후(committed) 강제로 바로 기록하지 않고 buffer manager에게 맡긴다.
(3) Steal policy
- 트랜잭션이 완료되지 않았더라도(uncommitted) disk에 기록한다.
⇒ 현대 DBMS는 no-force와 steal 정책을 사용한다.
To Output a block to disk
- block에 exclusive latch 를 건다. (read, write 불가)
- log flush 수행 (output)
- disk로 block을 output
- block에 걸린 latch 해제
Buffer 구현 장소에 따른 문제점
(1) real main-memory
- buffer가 자리를 차지하여 main-memory의 유연성 감소
- non-database system application들과 달리 main-memory에서 buffer를 잠시 내릴 수 없이 계속 자리를 차지해야 함
(2) Virtual memory
- dual paging problem : DB가 어떤 page의 block을 요청했는데, Buffer Manager 상에서는 main memory에 있다고 생각하지만 OS가 메모리 관리를 위해 swap space로 내쫓은 상태라면 해당 page를 다시 memory로 불러오는 추가 연산이 필요하다.
Fuzzy Checkpointing
- checkpointing하는 도중에는 모든 트랜잭션이 멈춰야한다. ⇒ 시간을 줄여보자
- 트랜잭션을 모두 멈춘다.
- <checkpoint L> log를 작성하고 log force 실시 (output)
- modified된 buffer block들의 목록 M을 작성한다.
- 트랜잭션이 다시 실행하도록 한다.
- M에 있는 modified buffer block들을 output한다.
- output될 때 block이 update되면 안된다.
- WAL 을 따른다.
- output이 끝나면, 가장 마지막 checkpoint한 위치를 last_checkpoint 로 disk에 저장한다.
⇒ 이로써 system이 checkpointing으로 인해 멈추는 시간이 줄어들었다.
⇒ +) incomplete checkpoint들도 안전하게 관리될 수 있다.(최소 끝에서 2번째는 유효하다.)

⇒ 위 그림에서 L2를 만드는 도중에 crash가 발생하면 last_checkpoint는 L1을 가리키게 된다.
⇒ L1이 복구 시작 지점이 된다.
19.6 Failure with Loss of Non-Volatile Storage
앞서 모든 개념들은 non-volatile storage에서 faile이 없다고 가정하였다. (log가 손실되는 경우 X)
실제로는 non-volatile storage에서도 loss가 발생할 수 있기 때문에 chekpointing과 유사한 방식으로 대비한다.
- 주기적으로 database를 stable storage로 dump 한다.
- main memory에 있는 모든 log들을 stable storage에 output한다.
- disk에 모든 buffer block을 output한다.
- database의 content들을 stable storage에 copy한다.
- stable storage에 <dump> log를 남긴다.
- fuzzy dump(online dump)도 가능 - system 사용 도중에 dump
'Computer Science > Database' 카테고리의 다른 글
| [데이터베이스] Chapter 18. Concurrency Control (0) | 2022.12.04 |
|---|---|
| [데이터베이스] Chapter 17. Transaction (0) | 2022.12.04 |
| [데이터베이스] Chapter 16. Query Optimization (0) | 2022.12.04 |
| [데이터베이스] Chapter 15. Query Processing (0) | 2022.10.13 |
| [데이터베이스] Ch 14. Indexing(2) - ch24. 내용 추가 : Hashing, Spatio-temporal Indexing (0) | 2022.10.10 |