![[운영체제]공룡책🦖 ch01. Operating System Introduction](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FLo6QH%2FbtrNeH730tz%2FRKqmcPZCV72amLMlOAXKd1%2Fimg.png)
Reference
1. Abraham Silberschatz, Greg Gagne, Peter B. Galvin - Operating System Concepts (2018)
2. Operating System class by Professor Sukyong-Choi at Korea University
이번 학기에 운영체제 수업을 들으면서 “Operating System Concepts 10th Edition” 책의 내용을 정리하려 합니다.
Ch.1은 전반적인 운영체제의 역할과 동작의 개요를 정리하는 내용이기 때문에 전체적인 흐름을 잡을 수 있습니다.
핵심 내용 위주로 요약하며 글을 작성하였습니다.
Operating System
- 운영체제는 컴퓨터의 hardware 자원을 분배 및 관리하는 software이다. (CPU, memory, I/O devices, storage)
- application program의 basis를 제공한다.
- computer와 user를 연결한다.
- **커널(Kerneal)**은 운영체제의 핵심이며, 운영체제는 커널과 커널 모듈들로 구성된다.
1.1 What Operating Systems Do
Computer System Structure
4가지 요소 = 하드웨어(CPU, 메모리, 입출력장치 등), 운영체제, 어플리케이션 프로그램(웹 브라우저, 워드프로세서 등), 유저
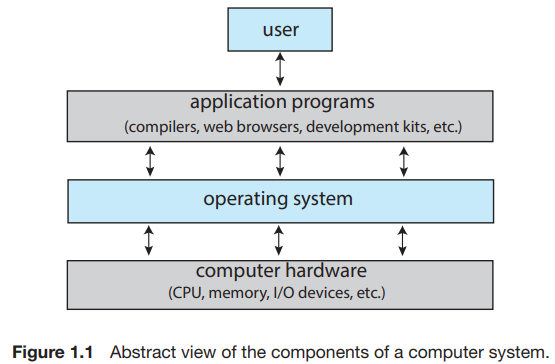
운영체제는 프로그램들이 동작할 수 있는 환경을 제공하고 hardware의 사용을 편성하고 조작합니다.
OS’s role
1.1.1 User View (사용자의 관점)
OS는 interface에 따라서 다음과 같이 다양하게 구분될 수 있습니다.
- 한 사용자가 독점 사용하도록 설계 : 사용자가 Resource utilization를 신경쓰지 않도록 한다.
- 여러 사용자가 여러 모바일 기기와 상호 작용하는 경우 : 사용자들이 resource를 공평하게 사용할 수 있도록 돕는다.
- user interface가 거의 없거나 아예 없는 경우
1.1.2 System View (시스템 관점)
- OS는 hardware와 가장 밀접하게 관련된 프로그램
- OS는 resource allocator : CPU, Memory space, Storage Space, I/O device 등의 resource를 효율적이고 공평하게 할당하고 관리한다.
- OS는 control program : I/O device와 user program을 control한다. 또한 program의 동작을 통제하여 error와 부적절한 사용을 방지한다.
1.1.3 Defining Operating System (정의)
The common functions of controlling and allocating resources are then brought together into one piece of software.
계속 반복되듯이 OS는 자원을 관리하고 할당하는 software입니다.
- Kernel (커널) : 컴퓨터에서 항상 실행되는 핵심 프로그램이자 운영체제의 핵심
- System programs : 운영체제와 연관되어 있으나 커널의 일부분은 아닌 프로그램
- Application programs : 그 이외의 프로그램
1.2 Computer System Organization
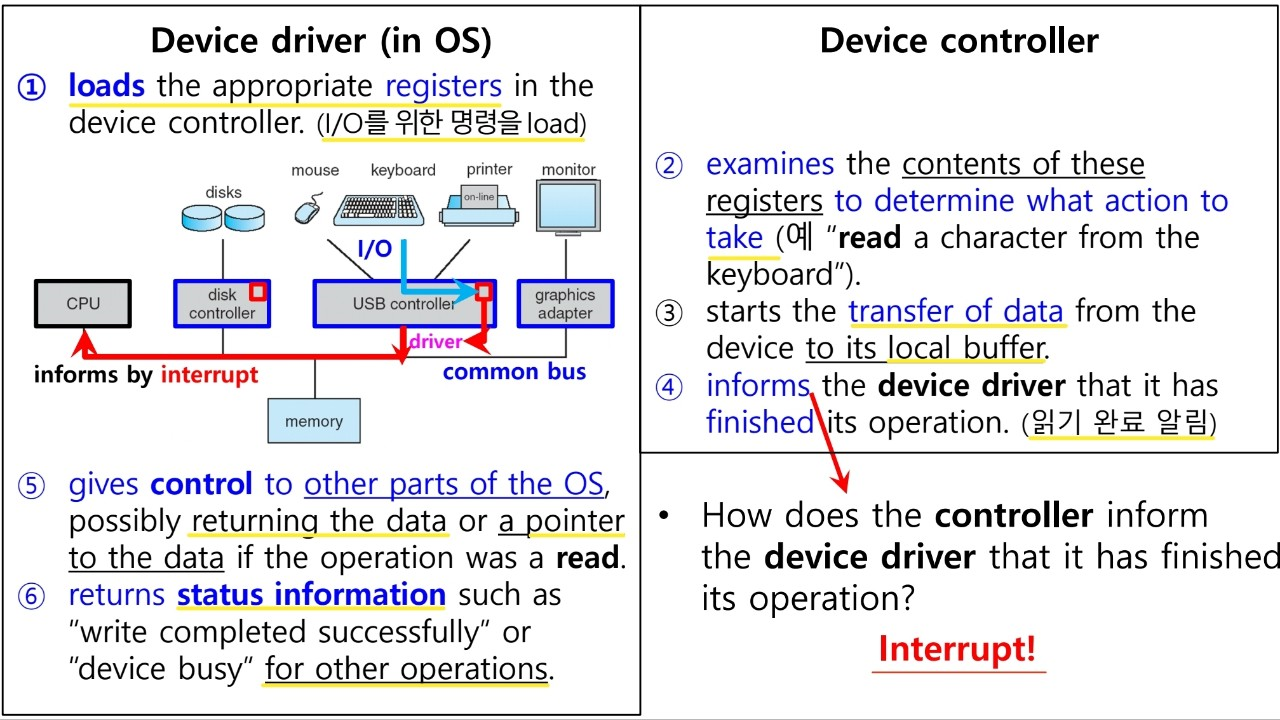
- Computer System은 여러 개의 CPU와 Device Controller로 구성되며, 이들은 Common bus로 이어져서 메모리를 공유한다. common bus는 데이터가 이동하는 일종의 통로이다. 또한 CPU와 Device controller는 병렬적으로 실행되고, memory cycle 내에서 경쟁한다.
- OS는 각 device controller(장치 측면)에 대해서 device driver(OS 측면)라는 장치 제어 프로그램을 가진다. device controller는 local buffer storage와 refister의 집합을 가진다.
- CPU를 통한 data 이동 : main memory ↔ local buffer of device controller I/O : device에서 device controller의 local buffer로의 data 이동 즉, CPU가 deivce controller를 통해서 device에게 I/O를 명령하는 것이다.
- Device controller는 interrupt를 통해 CPU에게 실행이 끝났음을 알린다.
Read 수행 시 동작 과정을 살펴보면 다음과 같습니다.
1.2.1 Interrupts
I/O 장치와 CPU는 병렬적으로 수행될 수 있기 때문에, device controller가 CPU에게 특정 이벤트 발생을 알리기 위해서 특정 Interrupt를 사용합니다.
보통 컴퓨터는 여러 작업을 동시에 처리하는데, 이때 당장 처리해야 하는 일이 생겨서 기존의 작업을 잠시 중단해야 하는 경우 인터럽트 신호를 보내고, 커널은 현재 작업을 멈추고 interrupt를 처리한 뒤 다시 기존 작업을 진행합니다.
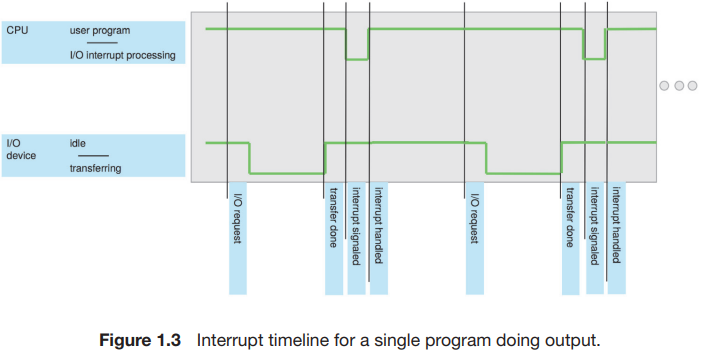
운영체제는 위 그림과 같이 Interrupt가 발생하면 해당 작업을 수행하게 됩니다.
- System bus를 통해 Interrupt가 CPU에 전달된다.
- 현재 작업을 멈추고 백업한 뒤, 해당 Interrupt를 처리하는 Service routine이 있는 곳으로 이동하여 해당 routine을 실행한다. (제어를 interrupt service routine으로 이동 후 처리)
- 수행이 완료되면, 백업된 정보를 바탕으로 이전 상태로 복구한다.
Interrupt는 매우 자주 발생하기 때문에 빠르게 처리되어야 합니다. 따라서 service routine의 위치를 나타내는 pointer table이 필요한 것입니다.
만약 CPU가 interrupt 신호를 받으면, 현재 작업을 멈추고 메모리의 어떤 고정된 위치(Fixed location)을 찾습니다. 해당 위치는 Interrupt Vector에 저장되어 있습니다.
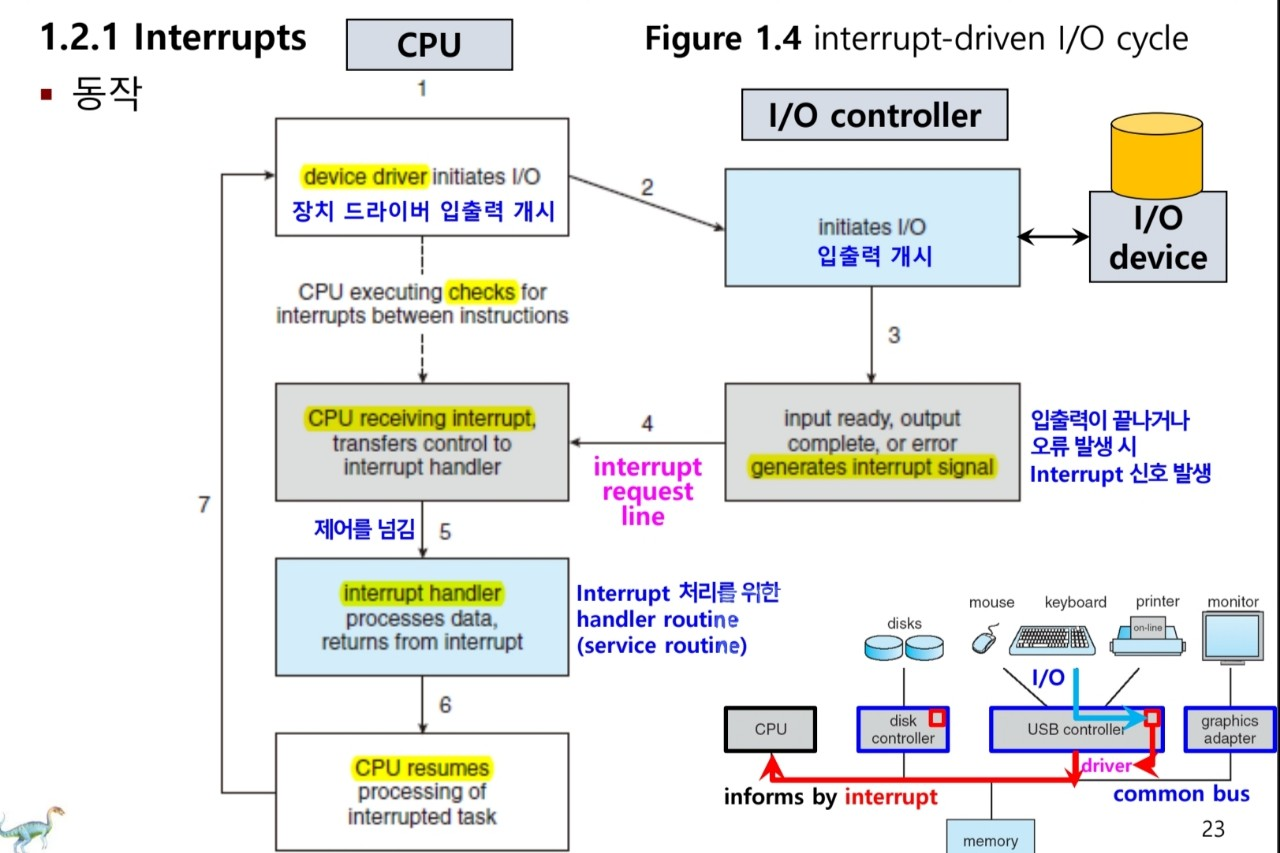
- Interrupt Vector : 각 I/O 장치에는 미리 index가 할당되고, 장치 별로 처리하는 service routine이 있다. 이러한 service routine의 주소가 저장된 테이블이다.
- Interrupt된 모든 상태 정보를 저장하여 마치 interrupt가 발생하지 않은 것처럼 이전 작업을 수행한다.
- Interrupt-requeset-line : CPU hardware,, I/O controller에서 발생시킨 신호를 감지한다.**
- nonmaskable interrupt : 복구 불가능(메모리 오류) 이벤트를 위해 예약된 interrupt.
- maskable interrupt : interrupt 무효화, 중요한 명령 실행 전 interrupt 끄기.
- Interrupt handling : 중요한 작업 전에는 interrupt 처리를 연기, interrupt에 level을 두어 중요도에 따라서 우선적으로 처리.
- Interrupt mechanism 덕분에 CPU가 device controller가 준비될 때 마다 asynchronous event를 처리할 수 있다.
- Interrupt chaining : interrupt vector보다 많은 장치가 있다면, interrupt vector의 각 요소들은 interrupt handlers list의 head를 가리킨다. (더 많은 interrupt 저장 가능)
1.2.2 Storage Structure
커널은 실행기(Executor)를 통해 프로그램을 실행시킵니다. 실행기는 기억장치(Storage)에서 exe파일(Windows의 경우)을 가져오고, 커널이 이것을 메모리에 할당해 실행시킵니다.
즉, 모든 program은 반드시 main memory에 올라야만 실행될 수 있습니다. 하지만 main memory는 DRAM으로 구현하여 휘발성이고 용량이 작기 때문에 별도의 저장장치가 필요합니다.
Von Neumann architecture - 저장된 프로그램 개념 도입
현대 컴퓨터 시스템은 기본적으로 폰 노이만 구조를 따릅니다.
프로그램과 데이터는 항상 메모리에 존재하는 것이 아니며, 메모리에 올라오고 나서야 사용할 수 있습니다.
Storage Hierarchy
storage는 속도, 크기 그리고 휘발성 여부에 따라서 다음과 같이 급을 나눌 수 있습니다.
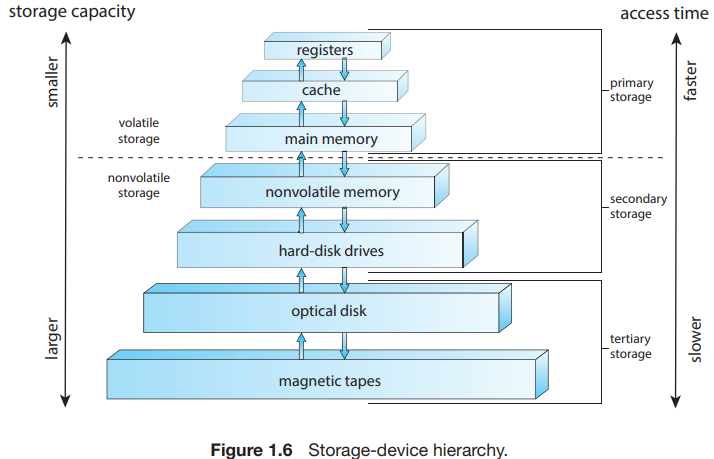
size와 speed는 항상 trade-off가 존재하여 용량이 클수록 속도가 느린 경향이 있습니다.
1.2.3 I/O Structure - interrupt-driven IO
interrupt 기반 입출력은 대용량 전송 시 높은 오버헤드가 발생합니다. → DMA 사용
- Direct Memory Access (DMA) : CPU 개입 없이 설정된 전체 block을 직접 전송 IO 완료를 알리기 위해 block당 하나의 interrupt만 발생된다.
- Device controller가 DMA를 수행하기 때문에 CPU는 다른 작업을 할 수 있다.
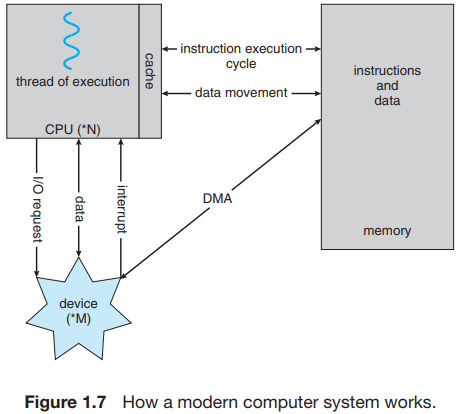
1.3 Computer-System Architecture
- core : 명령어 실행, 데이터 local 저장하는 요소 (register를 가짐)
- main CPU with core : 범용 명령어 셋을 실행
1.3.1 Single-Processor Systems
- 하나의 CPU(core 1개)를 갖는 시스템
1.3.2 Multi-Processor Systems (parallel system, tightly-coupled system)
- 여러 개의 Single-core CPU를 갖는 시스템
- processor들은 computer bus, clock, memory, peripheral device 등을 공유한다.
- throughput 증가 (processor 수와 성능이 정비례하지는 않는다.)
(1) Asymmetric MultiProcessing (AMP) - 각 processor에 특정 작업이 할당
- 서로 다른 칩에 각각 CPU가 있는 구조.
- processor가 실행하는 task가 구분됨
- core 간 기능 차이가 있다.
(2) Symmetric MultiProcessing (SMP) - 각 processor가 모든 작업을 수행
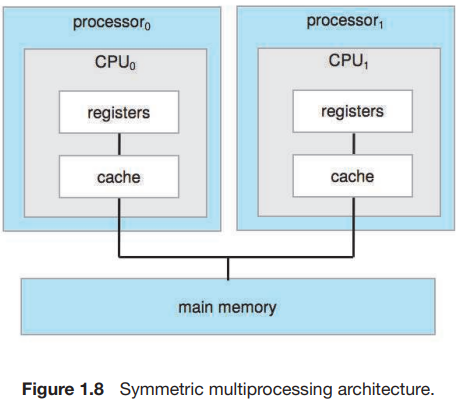
- 서로 다른 칩에 각각 CPU가 있는 구조.
- processor가 실행하는 task의 구분이 없음
- core 간 기능 차이가 없다.
- 각 CPU가 자신의 register와 cache로 개별 작업을 처리한다.
- 모든 processor가 system bus를 통해서 physical memory를 공유한다.
- 비효율적(한 쪽은 바쁘고 다른 쪽은 노는 경우 발생)
(3) Multicore systems - 하나의 CPU에 여러 core를 넣음, 진화된 구조

- 여러 core들이 한 chip에 있는 구조
- 한 칩에서 CPU core끼리 통신하기 때문에 칩 사이의 통신보다 훨씬 빠르다.
- power를 적게 쓴다.
- 각 core는 자신의 register set과 local cache를 갖는다 (그림 참고)
- L2 cache를 여러 processing core끼리 공유한다.
이러한 multi-processor system에서 CPU를 추가한다면 분명 성능이 향상될 수 있지만, 확장성은 떨어지게 됩니다. 또한 너무 많은 CPU를 추가할 겨우, system bus에 대한 경쟁을 초래하여 성능 저하로 이어집니다.
이에 대한 해결책으로 제시된 것이 NUMA입니다.
(4) NUMA(non-uniform memory access) - CPU 각각이 memory를 소유
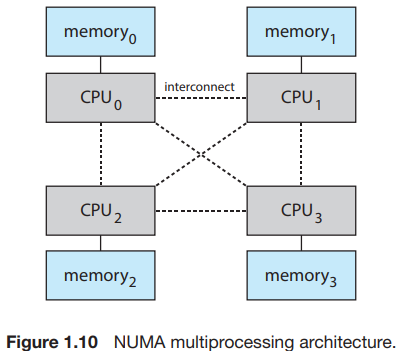
- 각 CPU에 작고 빠른 local bus로 접근 가능한 자신만의 메모리를 제공한다. 각 CPU는 local memory에 빠르게 접근 가능, system interconnect도 필요없음
- 모든 CPU가 공유 시스템에 연결되고, 모든 CPU가 한 물리 주소 공간을 공유한다.
- 확장성이 좋아 processor를 더 많이 넣을 수 있다.
- 만약 CPU가 local이 아닌 remote memory에 접근해야만 하면, latency가 발생.
- 다른 CPU의 local memory에 접근이 느리다
- ⇒ OS가 CPU 스케줄링과 memory 관리를 통해 해결
1.3.3 Clustered Systems
multiple-processor와 비슷하지만 다음과 같은 차이점이 있습니다.
- node(individual systems)들로 구성된다.
- 각 node들은 multicore system이다. 이들은 느슨하게 연결된다.
- storage를 공유하고 LAN이나 faster interconnect를 통해 연결된다.
즉, 멀티프로세서 시스템은 여러 CPU가 ‘하나’의 시스템을 이루는 것이지만, 클러스터 시스템은 여러 독립적인 시스템(node)들이 모여 하나의 시스템을 이루는 것입니다.
다음과 같은 특징이 있습니다.
- high-availablity service : 한 node가 고장나도 나머지가 정상 작동
- high-performance computing environments : 한 어플리케이션이 클러스터 내 모든 컴퓨터에서 병렬 실행, 작업 분배 ⇒ 컴퓨팅 파워가 훨씬 좋다.
- reliability : 안정성이 높다. graceful degradation(연속적인 서비스 제공), fault tilerant(failure에도 불구하고 계속 동작 가능)
두 가지로 분류됩니다.
- asymmetric clustering : node들의 기능이 비대칭 한 machine은 hot-standby mode(모니터링만 하고 대기중), 나머지가 사용됨
- sysmmetric clustering : node들의 기능이 대칭 서로 모니터링하고 노는 node없이 모두 사용된다.
1.4 Operating-System Operations
Initial program (bootstrap program)
컴퓨터를 실행하기 위해서는 초기 프로그램인 boorstarp program을 실행해야 합니다.
비 휘발성인 firmware로 HW에 저장되어 부팅 시 실행됩니다.
과정을 살펴보면 다음과 같습니다.
- 시스템을 초기화 시킨다. (CPU register, device controller, memory contents)
- OS 커널을 찾아서 메모리에 로드한다.
- 커널이 로드되어 실행되면 시스템과 사용자에게 서비스를 제공한다. ”systemd”이라는 프로그램은 리눅스에서 가장 먼저 실행되며, 다른 daemon을 시작한다
Events (이벤트의 처리)
이벤트는 interrupt를 발생시켜 신호를 보냅니다.
- Hardware interrupt : device에서 발생
- Trap or Exception : software error, system call(CPU의 도움이 필요한 경우 OS가 필요)
1.4.1 Multiprogramming and Multitasking
앞서 프로그램과 프로세스의 차이점은 설명하자면, 프로그램은 단순히 저장 장치에 저장된 파일에 불과하며, 이러한 프로그램이 메모리에 올라와서 실행되면 그것을 프로세스라고 부릅니다.
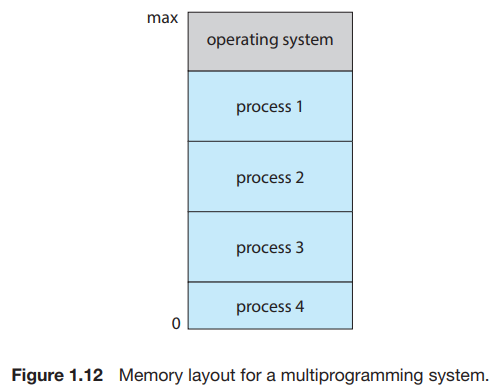
Multiprogramming
여러 프로그램을 메모리에 로드해 두고 한 프로세스가 대기 상태가 되면 다른 프로세스의 작업을 수행하는 시스템입니다.
Multitasking
multitasking은 multiprogramming의 논리적 확장입니다.
이는 process마다 작업 시간을 정해두고 번갈아가면서 작업하는 방식입니다.
switch가 자주 일어나서 사용자에게 빠른 응답 시간을 제공합니다.
CPU는 쉬지 않고 계속 다른 사용자 프로세스로 swith하며 작업합니다.
이를 위해서는 다음과 같은 기능이 필요합니다.
- memory management(9,10장) : 여러 process들이 동시에 memory에 접근해서는 안 됨
- CPU scheduling(5장) : 어떤 작업을 먼저 처리할 지 결정해야 함
- process scheduling, disk storage and memory menagement: 여러 process들을 동시에 실행시키기 위해서 서로 영향을 미치는 기능을 제한해야 함
1.4.2 Dual-Mode and Multimode Operation
만약 악의적인 사용자가 멋대로 OS 코드를 수정한다면 여러 문제가 발생할 것입니다.
이와 같은 일을 방지하기 위해서는 다른 프로그램이 잘못 실행되지 않도록 해야 합니다.
그래서 나온 것이 Dual mode입니다. 실행 모드를 구별하여 권한을 달리하는 것입니다.
- user mode (1)
- kernel mode (0) (= supervisor mode, system mode, privileged mode)
node의 전환은 system call에 의해 이루어집니다.
- user application이 OS에게 service 요청
- system은 반드시 user mode에서 kernel mode로 전환해야 한다.
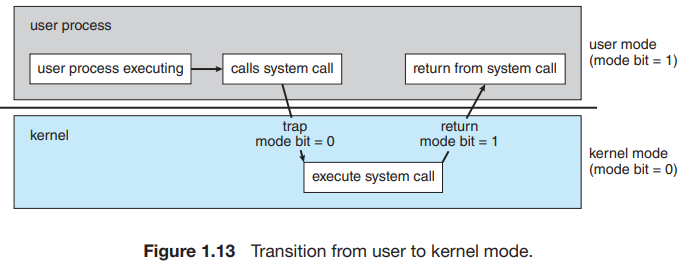
그 밖에 특징은 다음과 같습니다.
- boot 시 우선 kernel mode에서 시작하고, OS 적재 후 user mode에서 application을 실행
- trap or interrupt 발생 → user mode에서 kernel mode로 전환
- 이로써 잘못된 사용자로부터 OS를 보호
Privileged instructions (특권 명령어)
특권 명령어는 kernel mode에서만 실행됩니다.
만약 user mode에서 실행하려는 경우에는 명령이 무시됩니다.
Life sccle of instruction execution (명령어 실행 시 제어의 변화)
- 초기 제어는 OS가 가짐, 명령어들은 kernel mode에서 실행
- 제어가 user application에 주어지면, user mode가 설정됨
- 제어가 다시 OS로 넘어감(interrupt, trap, system call에 의해서)
System call
- processor 기능에 따라 다양한 방법으로 호출됨
- 보통 interrupt vector의 특정 위치로 trap으로 발생함.
- system에는 system call을 발생시키는 특정 명령어가 있다.
오류 처리 과정 - OS
- 사용자 프로그램이 mode 위반으로 fail 되면, 하드웨어가 OS에 trap을 발생 시킴
- interrupt vector를 통해 제어를 OS에 전송함
- 프로그램 오류 발생 시, OS는 프로그램을 비 정상적으로 종료시킴
- 적절한 오류 메시지를 제공하고 메모리를 덤프시킨다.
1.4.3 Timer
- 특정 시간이 지난 후 interrupt가 발생하도록 설정
- → 사용자 프로그램이 무한 루프나 system service 호출에 실패하여 제어가 OS로 넘어가지 않는 경우를 방지한다.
1.5 Process Management
다시 정리하면, program은 디스크에 저장된 파일이고(수동적), process는 메모리 위에서 실행되는 program입니다.(능동적)
1.5.1 Process Management
- program은 하나지만, process는 여러 개일 수 있다.
- process는 순차적으로 수행된다.
- 한 번에 하나의 명령만 수행된다.
- process가 병행 실행되도록 서브 process들을 생성하는 system call을 제공한다.
Program counter
process는 program이 어디까지 실행되었는지 북마크하는 program counter를 가지고 있습니다.
- Single-thread process : 하나의 program counter를 가짐
- Multi-thread process : 여러 개의 program counter를 가짐
1.5.2 Memory Management
Main memory는 매우 커다란 byte의 배열이며 각 byte에는 주소가 있습니다.
CPU는 instruction-fetch cycle동안 main memory에 올라온 명령어들을 읽습니다.
그리고 data-fetch cycle동안 mamin memory에 데이터를 읽거나 씁니다.
⇒ **명령어(Instruction)**들은 반드시 CPU에 의해 실행되기 전 memory에 load되어야 합니다.
Program 실행 과정
- program이 실행될 때 절대 주소로 mapping되고 memory로 load되어야 한다.
- program이 실행되면서 memory의 명령어와 데이터에 접근함
- program이 끝나면 memory 공간이 사용 가능함을 공표하고 다음 program이 load되고 실행된다.
OS의 memory management 활동
- memory의 어느 부분이 사용되고, 어느 process가 사용 중인지를 추적
- 필요한 memory 공간을 할당하고 회수함
- 어느 process/data가 memory에 들어가고 나갈 것인지를 결정함
1.5.5 Cache Management
Cache는 매우 빠르고 작은 저장 장치이며, Caching은 cache memory를 이용하여 컴퓨터의 속도를 높이는 기술입니다.
cache에 자주 사용되는 data를 미리 담아두고, CPU나 disk가 cache의 data를 참조할 수 있도록 합니다.
- 데이터는 사용되면서 cache에 일시적으로 저장됨
- 특정 데이터 필요 시 cache를 먼저 확인
- size에 제약이 있어 관리가 필요
- 파일의 중복성이 증가하지만, 속도 역시 증가함
- 지역성(Locality) 원리를 사용 시간지역성은 한 번 접근한 데이터에 다시 접근할 확률이 높다는 것이다. 공간지역성은 특정 데이터와 가까운 메모리 주소에 있는 다른 데이터들에도 접근할 가능성이 높다는 것이다.
Data coherency (데이터 일관성) - 반영이 안되면 접근을 제한
1. Multitasking 환경
multitasking 환경에서는 여러 process를 swtiching하면서 한 데이터를 공유해서 사용합니다.
이때, 여러 process가 특정 데이터 A에 접근할 때는 항상 A는 가장 최근에 update된 값을 보장해야만 합니다.
2. Multiprocessor 환경
multiprocessor 환경에서는 각 CPU가 local cache를 가집니다. 따라서 여러 cache에 A의 복사본이 동시에 존재하게 됩니다.
이때, A가 update되면 그 즉시 update 결과가 다른 모든 cache에 반영되어야 합니다.(Cache coherency)
3. distributed 환경
다른 컴퓨터에 한 파일에 대한 여러 복사본들이 존재하게 됩니다.
이때도 그 파일을 수정하게 되면 그 즉시 모든 replica를 갱신해야 합니다.
'Computer Science > Operating System' 카테고리의 다른 글
| [운영체제] 공룡책🦖 ch06. Synchronization Tools (0) | 2022.11.23 |
|---|---|
| [운영체제] 공룡책🦖 ch05. CPU Scheduling (0) | 2022.11.23 |
| [운영체제] 공룡책🦖 ch04. Threads & Concurrency (0) | 2022.10.24 |
| [운영체제] 공룡책🦖 ch03. Processes (0) | 2022.10.08 |
| [운영체제] 공룡책🦖 ch02. Operating-System Structures (0) | 2022.10.08 |