![[운영체제] 공룡책🦖 ch05. CPU Scheduling](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FMZeFI%2FbtrRVuJC1nC%2FGMfwW3NOfgnDNeH9S1VEN0%2Fimg.png)
Reference
1. Abraham Silberschatz, Greg Gagne, Peter B. Galvin - Operating System Concepts (2018)
2. Operating System class by Professor Sukyong-Choi at Korea University
3. 혼자 공부하는 컴퓨터구조 + 운영채재 (강민철)
중요한 내용 위주로 요약 && 정리했습니다.
목차
- Basic Concepts
- Scheduling Criteria
- Scheduling Algorithms
- Tread Scheduling
- Multi-Processor Scheduling
- Real-Time CPU Scheduling
- Operating Ststems Examples
- Algorithm Evaluation
5.1 Basic Concepts
Mulitiprogramming을 위해서
- CPU 사용률을 최대화하기 위해, 프로세스들을 항상 실행해야 한다.
- 프로세스는 I/O 요청과 같은 이벤트가 있을 경우 잠시 wait 해야 됨
- 이러한 waiting time이 그저 낭비된다면 useful한 work을 완료하지 못할 것.
⇒ 이를 해결하기 위해서 한 순간에 다수의 프로세스를 메모리에 유지시킨다.
⇒ 한 프로세스가 wait하면, OS CPU를 뺏은 뒤 다른 프로세스에게 할당한다.
⇒ multicore system으로 확장되어 CPU를 busy한 상태로 유지
CPU-I/O Burst Cycle
- CPU 스케줄링은 프로세스들의 성질에 의해 결정됨
- 프로세스 실행은 CPU execution과 I/O wait로 구성된다.
- 그리고 CPU burst로 시작한다.
- 마지막 CPU burst 는 실행 종료를 위한 시스템 요청으로 끝남

⇒ 번갈아가면서 실행
Durations of CPU bursts
- I/O-bound program : many short CPU bursts. 입출력 짧게 자주
- CPU-bound program : few long CPU bursts
Frequency Curve
→ 짧은 CPU burst가 대부분, 긴 CPU burst는 일부
→ 시간에 따라 스케줄링 조절
5.1.2 CPU Scheduler
- CPU가 idle 상태가 될 때마다, OS는 ready queue에서 한 프로세스를 골라서 실행함
- CPU 스케줄러는 실행 준비가 된 메모리 내 프로세스로부터 골라 CPU를 할당함
- ready queue의 모든 프로세스들은 CPU에서 실행되기를 기다리며 대기함
- 큐 내 레코드들은 일반적으로 프로세스의 PCB이다.
5.1.3 Preemptive(선점) and Nonpreemptive(비선점) Scheduling
결정해야 할 4가지 경우
- I/O 요청, 자식 프로세스의 종료를 위한 wait() 호출
- 프로세스 종료
- interrupt 발생
- I/O 완료
No choice(1,2) : 프로세스가 자의로 CPU 할당을 해제 → 새로운 프로세스가 선택되어 수행됨
⇒ nonpreemptive (cooperative) 스케줄링
a choice(3,4) : 기존에 실행 중인 프로세스로 부터 CPU를 빼앗아 자신에게 할당 (자원을 선점)
⇒ preemptive 스케줄링
Under nonpreemptive scheduling
- CPU가 할당되면, release 할 때까지 계속 점유함
Under preemptive scheduling → 이슈 발생 (아직 처리 완료 전에 CPU를 뺏김)
- shared data 접근
- kernel mode에서의 preemption
- interrupt 처리로 중요한 작업 중일 때
- Access to shared data in Preemptive
- 여러 프로세스 간 데이터 공유 시 경쟁 조건 초례 (race conditions)
ex) 데이터를 공유하는 두 프로세스
- 공유 데이터를 update 하는 동안 선점되고 두 번째 프로세스가 실행됨 → inconsistent state 일 수 있음; 데이터 일관성 문제
2. Preemptive in kernel mode
- 커널 설계에 영향
- systen call 처리 동안, 커널은 프로세스를 위한 활동으로 바쁨
- 프로세스가 커널 데이터 처리 도중 선점되고 커널이 그 데이터를 읽거나 수정한다면 혼란
Design of OS kernel : nonpreemptive and preemptive
nonpreemptive kernel
- system call 완료를 기다림, IO 완료까지 block 되기를 기다림
- inconsistent 상태에서는 선점 x
- 주어진 시간 내에 실행을 끝내야 하는 실시간 컴퓨팅 지원 X
preemptive kernel
- 기다리지 않고 선점함
- 공유 커널 잘료에 접근 시 경쟁 조건 방지를 위한 메커니즘 필요 (Ex - mutex locks)
3. Interrupts
- interrupt에 영향을 받는 code 부분은 동시 사용으로부터 보호되어야 함
- OS가 interrupt를 처리하지 않으면, input을 잃거나 덮어써질 수 있음
- interrupt code는 동시 접근되지 않음 → entry에서 disable, exit에서 reenable 해서 다른 interrupt가 걸리지 않도록 함
- interrupt를 불능화하는 code는 자주 발생하면 안됨, 몇 개의 명령어만 포함
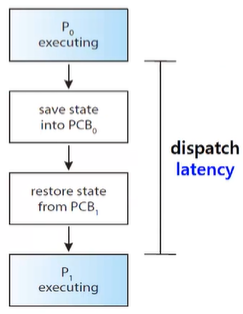
5.1.4 Dispatcher
- CPU scheduler가 선택한 프로세스에게 CPU core의 제어를 넘기는 모듈
functions
- switching context (프로세스 간 문맥 교환)
- 사용자 모드로 전환
- 프로그램 재개를 위해 사용자 프로그램 내 적절한 위치로 이동
dispatch latency
- dispatcher가 한 프로세스를 멈추고 다른 프로세스를 실행하기 위한 시간
→ 최대한 줄여야 한다
vmstat 명령어 : context switching 정보를 조회
voluntary context switch : 현재 사용 불가능한 자원 요청하여 프로세스가 CPU 할당을 포기함;
(ex_ blocking for I/O)
nonvoluntary context switch : time slice가 만료되거나 우선 순위 높은 프로세스가 선점한 경우 CPU를 뺏김
5.2 Scheduling Criteria
- CPU 스케줄링 알고리즘 별 특성이 다르다 → 상황에 따라 선택
- criteria → 스케줄링 알고리즘 비교를 위한 기준
Scheduling Criteria (CPU 스케줄링 비교 기준)
- CPU utilization (이용률) : 가능한 CPU를 바쁘게 하도록
- Throughput (처리량) : 시간 단위 당 완료된 프로세스의 수로 작업량을 측정
- Turnaround time (처리 시간) : 프로세스 실행의 총 소요 시간 = 대기 시간 + 실행 시간 + IO 시간
- Waiting time (대기 시간) : ready queue에서 기다린 총 시간/process의 실행, IO 시간에 영향 X
- Response time (응답 시간) ; 첫 응답이 시작되는 데까지 걸리는 시간. 중간에 결과가 나온다면 그것이 기준이 됨. 응답 시작까지의 걸리는 시간이지 최종 응답 출력까지의 시간이 아니다.
⇒ 평균 보다는 최대/최소값을 최적화 시킨다!!
- 모든 사용자가 좋은 service를 얻도록 보장하기 위해 최대 응답시간을 최소화해야 함
- interacitve(대화식) 시스템에서는 응답 시간의 편차를 최소화해야 함
- 평균 속도가 빠르고 편차가 큰 것 보다는 합리적/예측가능한 응답시간을 갖는 시스템이 더 좋음
- CPU utilization (CPU 이용률) → 최대화
- throughput (시간 단위 당 완료된 프로세스의 수) → 최대화
- turnaround time (프로세스 실행에 소요되는 시간) → 최소화
- waiting time (ready queue에서 기다린 총 시간) → 최소화
- response time (첫 응답이 시작되는 데까지 걸리는 시간) → 최소화
⇒ 편의를 위해, process당 하나의 CPU burst만 고려(ms), 알고리즘 비교 기준은 평균 대기 시간, 한번에 하나의 프로세스만 실행
5.3 Scheduling Algorithms
- ready queue 내의 어떤 프로세스에게 CPU core를 할당할 것인가의. 문제를 해결
5.3.1 First-Come, First-Server Scheduling (FCFS)
- CPU를 처음 요청한 프로세스가 CPU를 처음으로 할당 받는다
⇒ 새로운 프로세스가 ready queue에 들어가면 해당 PCB가 큐 끝에 연결된다!
⇒ CPU가 가용해지면, 큐의 앞에 있는 process에 할당됨
- nonpreemptive scheduling이다! → CPU가 할당되면, process가 종료나 IO요구로 CPU를 해제할 때까지 점유함
- 따라서 interactive system에서는 안 좋다.
단점 : 평균 대기 시간이 종종 꽤 길다.
Gantt chart : 특정 스케줄 기법을 도시한 막대 차트
- process 별 start/finish time을 포함
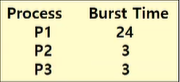
- P1, P2, P3 순서

⇒ (0 + 24 + 27) /3 = 17 ms
- P2, P3, P1 순서
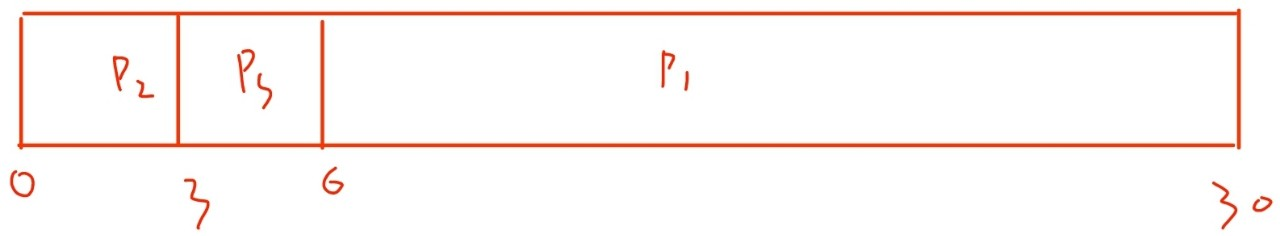
⇒ (0 + 3 + 6) /3 = 3 ms : 훨씬 감소!
따라서, FCFS 정책에서 평균 대기 시간은
- 최소가 아니다
- CPU burst가 크게 다르다면, 평균 대기 시간이 크게 달라짐
Convoy effect (호위 효과)
- 모든 다른 process들이 하나의 긴 process가 CPU를 양도하기를 기다림
- ⇒ 긴 process 뒤에 짧은 process들이 있는 상황을 의미
- 짧은 process가 먼저 실행되는 경우보다 CPU와 Device 이용률이 줄어듦 ⇒ 비효율
5.3.2 Shortest-Job-First Scheduling (SJF)
- next CPU burst가 최소인 process에 CPU가 할당됨
- 두 process의 값이 동일하면, FCFS를 적용
- 프로세스의 전체 길이가 아닌, next CPU burst의 길이에 좌우됨
- Optimal 하다 ⇒ 주어진 process 집합에 대해 평균 대기 시간이 최소
short process가 앞으로 이동해서 대기 시간을 줄임(더 이득) >> long process의 대기 시간이 증가
단점 : 하지만, next CPU burst 길이를 알 수 없으므로, CPU 스케줄링 수준에서 구현 불가능
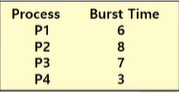

⇒ ( 3 + 16 + 9 + 0 ) /4 = 7 ms
approximate SJF scheduling
- next CPU burst 값을 예측 →
- 이전 CPU burst와 비슷하다고 가정
- 측정한 이전 CPU burst의 길이를 지수평균하여 예측함
- next CPU burst의 근사치를 계산하여, 예측한 CPU burst가 가장 작은 process를 선택한다!
- Exponential Average


- ⇒ 알파값에 따라서 현재 값과 과거 값의 비중을 결정할 수 있다
- Example : 알파 = 1/2 , 타우 = 10
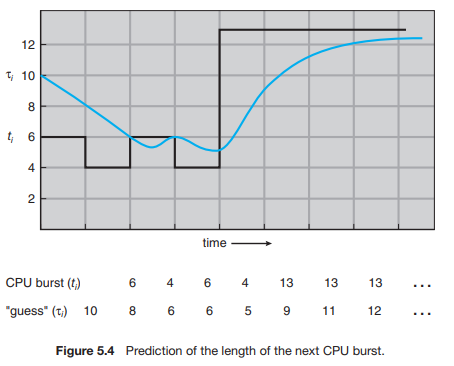
- ⇒ 어느정도 근접하다!
- 이전 process가 실행되는 동안, 새 process가 ready queue에 들어오면 선점/비선점을 선택함
“새로 들어온 process의 next CPU burst < 현재 실행 중인 process의 남은 CPU burst “ 인 경우
→ preemptive SJF 알고리즘 : 무조건 짧은 것을 먼저 선점하므로, 새로 들어온 process가 선점
→ nonpreemptive SJF 알고리즘 : 현재 실행 중인 process가 끝날 때 까지 기다린다
- Preemptive SJF scheduling ( = shortest-remaining-time-first scheduling


P2가 끝났을 때, P1 : 8-1 = 7, P4 : 5 이므로 P4가 선점한다.
P1이 실행 중이더라도 더 짧은 process들이 선점하도록 Gantt Chart를 그린다!
⇒ { (10-1) + (1-1) + (17-2) + (5-3) } /4 = 6.5 ms
- Nonpreemptive SJF scheduling


5.3.3 Round-Robin Scheduling (RR) : FCFS + Preemption
- 시스템이 process 간 전환이 가능하도록 선점이 추가됨
- time quantum(=time slice)를 정의 - 시간 단위
- 원형 ready 큐를 돌며 하나의 시간 할당량(time quantum) 동안 CPU를 할당한다.
- new 프로세스는 ready queue의 tail에 추가됨
- CPU가 가용해지면, ready queue의 첫 process를 선택 → 시간 할당량 후 interrupt 되도록 timer 설정 → 프로세스를 dispatch 함
- 1 time quantum 이상을 연속으로 CPU 할당 받는 프로세스는 없다.
- ⇒ 따라서 preemptive이다.
⇒ CPU burst가 1 time quantum보다 적으면 작업 다 하고 스스로 CPU를 해제함, 더 긴 경우 실행 중이던 프로세스는 ready queue 끝에 추가된다.
→ RR 방식은 평균 대기 시간이 상대적으로 긴 경향이 있다.
- time quantum : 4 ms, time 0에 p1, p2, p3 순으로 들어옴


⇒ ( 6 + 4 + 7 ) /3 = 5.66 ms
- n 프로세스, q time quantum → 각 프로세스는 1/n CPU time, 최대 q 시간
- RR 알고리즘의 성능은 time quantum 크기에 따라 크게 좌우된다.
만약 time quantum이 너무 크면 FCFS 방식과 같을 것
너무 작다면(1ms) context switch가 매우 많이 일어나게 됨
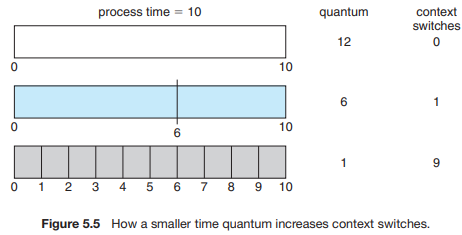
⇒ 적어도 time quantum은 context switch time보다 더 커야 된다 (대략 10배)
- Turnaround Time 역시 time quantum의 크기에 의해 크게 좌우된다.
대부분의 process가 한 time quantum 내에 next CPU burst를 끝내면 총 처리 시간은 향상된다,

but, time quantum이 너무 작게 설정하면 더 많이 switch 하므로 평균 처리 시간이 오히려 증가한다.
⇒ time quantum이 증가해도 process 집합의 평균 처리 시간이 꼭 향상되는 것은 아니다.
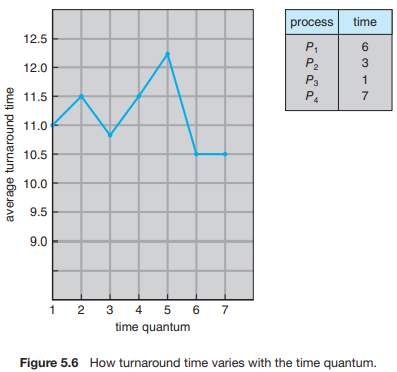
→ time quantum 이 3일 때 : 10.75 / 6일 때 : 10.5
→ 오히려 감소함!
+) time quantum이 context switching time 에 비해 커야 하지만, 너무 커도 안됨 (FCFS로 퇴보)
5.3.4 Priority Scheduling
- 우선 순위는 각 process와 연관, 우선 순위가 높은 process에 CPU가 할당됨
- 번호가 낮으면 먼저 CPU 할당 (구현에 따라 다름)
- 우선 순위가 같다면 FCFS order에 따른다
- SJF는 우선 순위 스케줄링의 특별한 경우 중 하나이다.
→ CPU burst가 크면, 우선 순위가 낮은 것


⇒ { (6-0) + (0-0) + (16-0) + (18-0) + (1-0) } /5 = 8.2 ms
우선 순위는 내/외부적으로 정의한다.
- 우선 순위 계산을 위해 측정 가능한 값을 사용한다.
시간 제한, 메모리 요구, 사용한 파일의 수, IO 대 CPU 비율
- OS 외부에서 기준에 의해 정해짐
프로세스 중요도, 비용, 작업 후원 부서, 정치적 요인
Preemptive and Nonpreemptive Priority scheduling
→ 프로세스가 ready queue에 도착 시, 실행 중인 프로세스와 우선 순위 비교
- Preemptive priority scheduling : 새로 도착한 process의 우선 순위 → 현재 실행 중인 process의 우선 순위
- Nonpreemptive priority scheduling : 우선 순위가 높은 새로 도착한 process를 ready queue의 앞에 배치함
Major Problem : indefinite blocking or starvation
- 실행될 준비가 되었으나 CPU를 대기 중인 프로세스; block된 것으로 간주됨
- 우선 순위가 낮은 일부 프로세스는 무한 대기할 수 있음 (영원히 할당 못 받음)
- 부하가 큰 시스템에서, higer-priority process들이 계속 들어오는 경우
이 경우 다음과 같은 일이 일어난다.
⇒ 부하가 낮을 때는 결국 process 실행
or 시스템이 crash되어 unfinshed low-priority process들을 lose 함
starvation 해결책
1. Aging
- 장시간 대기 중인 process의 priority를 점차 높여줌
- 주기적으로 waiting process의 priority를 1씩 증가시킨다.
2. combine Round-Robin and Priority Scheduling
- 가장 우선 순위가 높은 process를 실행, 동일 우선 순위의 경우 RR로 스케줄함
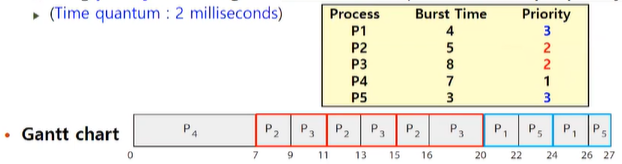
⇒ P2, P3 끼리 RR / P1, P5끼리 RR
⇒ starvation을 완벽하게 해결하지는 못함
5.3.5 Multilevel Queue Scheduling
기존에는 우선 순위 가장 높은 것을 고르기 위해 O(n) search 시간이 걸린다.
- 우선 순위마다 다른 queue를 운영

⇒ 단순히 우선 순위가 가장 높은 queue에 있는 process를 스케줄한다!
- priority는 한 번 설정되면 바꾸지 않는다 (정적) → process는 실행 시간 동안 같은 큐에 존재
- process를 type에 따라 개별 queue로 분할하기 위해 사용 가능실시간으로 처리해야 하는 real-time process들의 우선 순위가 가장 높다

- ⇒ queue 별로 독립적인 스케줄링 알고리즘을 가진다!!
foreground queue → RR 알고리즘
background queue → FCFS 알고리즘
이때, 우선 순위가 높은 큐에 프로세스가 없어야만 우선 순위가 낮은 프로세스들이 실행될 수 있다
⇒ queue 간 스케줄링 알고리즘 존재
- scheduling among the queues
1. fixed-priority preemptive scheduling
각 queue는 고정된 우선 순위를 가지고, 상위 process들의 큐가 비지 않으면 하위 process는 실행 X
2. time-slice among the queues
queue 별로 time slice를 부여하고, queue 내의 process들을 스케줄함
5.3.6 Multilevel Feedback Queue Scheduling
1. Multilevel queue scheduling 알고리즘
- process가 system 진입하면 하나의 queue에 영구적으로 할당됨
- queue 간 이동 x
- low scheduling overhead (장점)
- inflexible (단점)
이를 보완하여
2. Multilevel feedback queue scheduling 알고리즘
- process가 queue 간 이동이 가능
- CPU burst의 특성에 따라 process를 구분함
- process가 CPU time을 너무 많이 쓰면 lower-priority queue로 이동된다
- CPU burst가 짧으면 higher-priority queue로 이동된다.
- lower-priority queue에서 너무 오래 대기하면 높은 우선 순위의 queue로 이동시킨다.
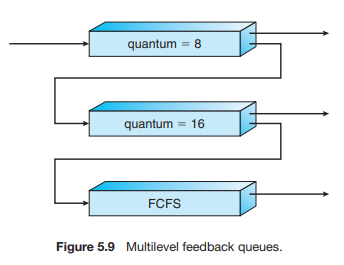
- ⇒ time quantum 내에 못 끝내면 선점됨 + 우선 순위가 낮은 큐로 이동됨
- 밑에서 너무 오래 기다린 프로세스는 우선 순위가 높은 큐로 이동시킴 → starvation 방지
5.4 Thread Scheduling
OS에 의해서 process가 아닌, kerenl-level thread가 스케줄된다.
user level thread는 thread library에 의해 관리되고 커널은 존재를 모른다.
→ CPU에서 실행되려면 연관된 kernel level thread에 mapping 되어야 한다!
5.4.1 Contention Scope
user level과 kernel level thread는 스케줄 방식에서 차이가 있다

1. Process contention scope (PCS)
- user level thread를 스케줄
- 프로세스 내 스레드 간 CPU core 경쟁
- 높은 우선 순위를 가진 스레드를 선택함
- 실행 중인 스레드를 선점
2. System contention scope (SCS)
- kernel level thread를 스케줄
- 시스템 전체 스레드 간 CPU core 경쟁
- 스레드 라이브러리가 가용 LWP에 스케줄 → OS가 LWP의 kernel thrad를 물리적 CPU core에 스케줄
5.4.2 Pthread Scheduling
- PTHREAD_SCOPE_PROCESS : PCS scheduling - user level 스레드를 가용한 LWP에스케줄함
- PTHREAD_SCOPE_SYSTEM : SCS scheduling - 각 user lelvel 스레드에 대한 LWP를 생성하고 연결함; LWP → core에 일대일 매핑
5.5 Multi-Processor Scheduling
multiprocess : 여러 물리 processor를 제공하는 시스템; processor 당 한 core
여러 CPU가 가용하다면, 부하 공유가 가능해짐
- Multicore CPU (homogeneous)
- Multithreaded cores (homogeneous)
- NUMA systems (homogeneous)
- Heterogeneous multiprocessing
5.5.1 Approaches to Multiple-Processor Schduling
1. Asymmetric Multiprocessing (AMP)
- 비대칭 (기능적으로 다름) : Master / oters
- master server가 모두 처리
- 나머지는 user code만 실행
2. Symmetric Multiprocessing (SMP)
- 독립적으로 작업 가능
- CPU마다 똑같은 일 처리 가능
- 각 프로세서 별로 스케줄링 가능
- 각 프로세서 별 스케줄러가 ready queue를 확인, 실행할 스레드를 선택함
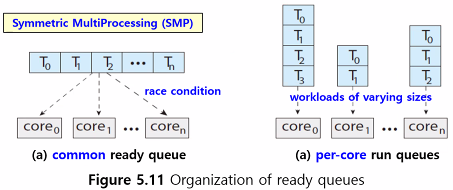
→ 하나의 공통 ready queue / 개별 스레드 큐
(a) common ready queue : 하나의 공통 ready queue
- race condition (경쟁 조건) 발생 : 동일 스레드를 스케줄하지 않도록, 큐에서 스레드가 없어지지 않도록 보장
- locking
(b) per-core run queues : 개별 스레드 큐
- 캐시 메모리를 더 효율적으로 사용 (계속되는 처리에 core 내 캐시 메모리 데이터를 이용 가능)
- 큐마다 부하의 양이 다름 → load balancing이 필요
- 모든 프로세스들 간 부하를 균등하게 하는 균형 알고리즘이 사용됨
5.5.2 Multicore Processors
Memory stall
- 메모리 접근 시 data가 가용해지기를 기다리며 낭비되는 시간
- ← 현대 프로세스는 메모리보다 속도가 훨씬 빨라서 cache miss 발생
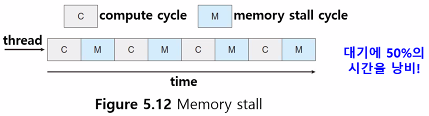
이를 해결하기 위해서
- 둘 이상의 hardware thread를 한 core에 할당함
- 한 hardware thread가 메모리를 기다리며 중단되면, core가 다른 thread로 전환됨

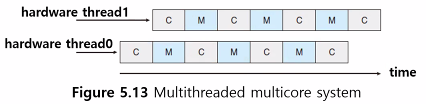
- 각 hardware thread는 각 architectural state를 유지
- OS 입장에서는 hardwoare thread를 software thread를 실행하는 논리적인 CPU로 보고 스케줄링함 (chip multithreading; CMT)

processor : 4 computing core / each core : 2 hardware thread ⇒ OS 입장에서는 8개의 logical CPUs
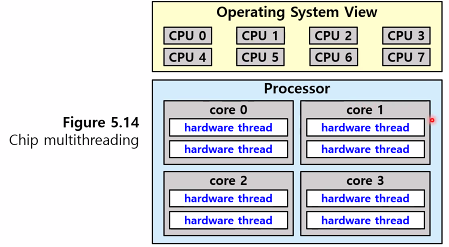
core를 멀티 쓰레드 하는 방법
1. Coarse-grained multithreading
- 처리에 시간이 많이 걸리는 이벤트 발생 시 switch함
- 이번트 발생 전까지 한 core에서 실행됨
- core에 다른 스레드가 실행되기 전에 명령 pipeline이 비워져야 함 → switching cost가 높음
- 새 스레드 실행 시, 새 명령어들로 pipeline을 채움
2. Fine-grained ( or interleaved ) multithreading
- 세밀한 단위에서 switch함
- 구조적 설계에서 스레드 교환 회로를 포함 → 비용이 적음
Processing core는 한번에 하나의 hardware thread만 실행함
물리적 core 자원(캐시/파이프라인)은 hardware thread간 공유
multithreaded, multicore processor는 두 level의 스케줄링이 필요하다
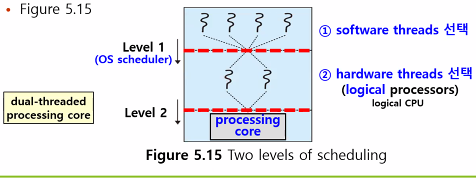
1. OS에 의해 hardware thread에서 실행될 software thread를 선택하는 단계
- 스케줄링 알고리즘 사용
2. 각 core에서 실행될 hardware thread를 선택하는 단계
- a. simple round-robin algorithm
- b. 이벤트 발생 시 urgency 값을 비교함
자원 공유 정보를 활용한 효과적인 스케줄링
- 같은 core에 스케줄되면, 자원 공유로 느려질 수 이씅ㅁ
- 자원 공유하지 않는 logical processor에 스케줄
5.5.3 Load balancing (부하 균등)
SMP
- 멀티프로세서의 이점을 최대한 활용하기 위해 부하를 균등하게 유지!
- 그렇지 않으면, 하나 이상의 프로세서가 idle 상태일 때 다른 프로세서들은 부하가 클 수 있음; ready ququ에서 CPU를 기다리는 상황
Load balancing
- SMP에서 모든 프로세서들의 부하를 동일하게 유지하는 것
- 각 프로세서별로 자신의 ready queue를 갖는 시스템에서는 필요함
- common run queue를 사용하는 system에서는 필요없다
Load balancing 방법
1. Push migration
- 특정 task가 주기적으로 load를 검사하여 imbalance가 발견되면, thread를 move/push 함으로써 load balancing 함
2. Pull migration
- idle processor가 busy process로부터 waiting task를 pull함
→ push와 pull을 병렬적으로 구현 가능
load balancing의 의미
1. 동일한 개수
- 단순히 모든 큐에 대략 동일한 수의 스레드가 있는 것
2. 동일한 우선순위
- 모든 큐에 스레드 우선순의가 동일하게 분포함
5.5.4 Processor Affinity
→ 스레드가 특정 processor에서 실행될 때 캐시 메모리는?
Warm Cache
- 스레드가 최근 접근한 데이터가 프로세서의 캐시를 채움
- 스레드에서의 연속적인 메모리 접근은 캐시 메모리에서 처리됨 → warm cache
Load balancing으로 migration이 발생한다면?
- migrate 이전 프로세서의 캐시 메모리는 무효가 됨 (warm cache 무효)
- migrate 이후 프로세서의 캐시가 채워진다
→ 로드 밸런싱의 이점 VS warm 캐시의 이점
→ 보통은 migiration을 avoid한다!
- 프로세스는 현재 실행 중인 프로세서에 대해서 선호를 가짐! (affinity)
스레드 큐의 구성이 프로세서 선호도에 영향을 미침
- common ready queue : 스레드는 임의의 processor에서 실행 가능, 새로운 processor에서 스케줄 된다면, 캐시가 새로 채워져야 함
- private, per-processor ready queues : 스레드는 항상 같은 processor에서 실행됨, warm cache의 내용을 활용함
Processor Affinity의 형태
1. soft affinity
- OS는 process가 동일 processor에서 실행되도록 노력함, 보장은 안됨
- 노력은 하지만 load balancing으로 processor 간 이주 가능
2. hard affinity
- system call로 프로세스가 실행될 수 있는 프로세서의 집합을 지정함
- 특정 프로세서에서 실행되도록 보장
메인 메모리 구조가 processor affinity에도 영향을 줌
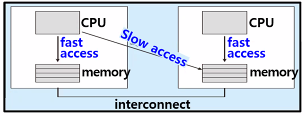
- 특정 CPU에 스케줄된 스레드로부터 가까운 메모리를 할당
- NUMA-aware인 경우 가까운 메모리에 할당!
5.5.5 Heterogeneous Multiprocessing
- 모든 프로세서가 기능 면에서 동일 → 스레드는 임의 core에서 실행 가능
- load balancing, processor affinity, NUMA 등에 따라 메모리 접근 시간이 다름
Heteroheneous multiprocessing (HMP)
- core들이 기능적으로 다를 수 있음
- 스레드가 특정 목적으로 특정 core에서 실행될 수 있음
- task의 특정 요구에 기반하여 특정 core에 할당함으로써 전력 소비를 더 잘 관리
- Big core : 전력 많이 소비 → 짧은 시간 동안만 사용
- Little core : 전력 적게 소비 → 긴 시간 사용
5.6 Real-Time CPU Schduling
- soft real-time systems : 중요한 실시간 process가 언제 스케줄 되는지를 보장하지 않음, process가 덜 중요한 process보다 우선적으로 스케줄 된다는 것만 보장함
- hard real-time systems : task는 반드시 deadline까지 서비스 되어야 함, deadline 이후의 서비스는 서비스 받지 않은 것과 동일하게 취급
5.6.1 Minimizing Latency
- Event-driven nature
- system은 event가 발생하기를 실시간으로 대기
- sw적 이벤트 : 타이머 만료 / hw적 이벤트 : 원격 제어 차량의 장애물 접근 감지
- 최대한 빨리 응답/서비스 해야 함
- Event latency : 이벤트 발생 ~ 서비스 될 때까지의 시간

실시간 시스템 성능에 영향을 주는 두 지연시간
- Interrupt latency
- Dispatch latency
1. Interrupt latency : 인터럽트 발생 ~ 인터럽트 서비스 루틴 시작
- OS는 실행 중이던 명령을 완료하고 발생한 인터럽트 type을 결정함
- 현재 process의 state를 저장하고, ISR을 이용한 인터럽트 처리
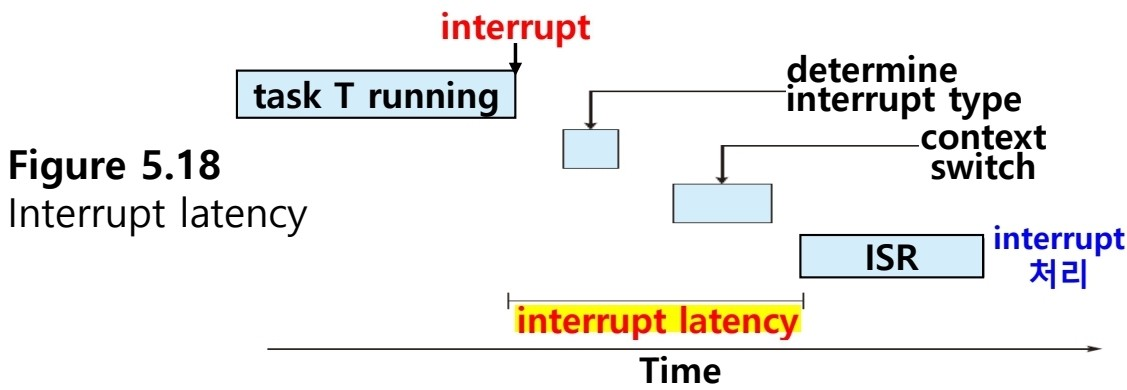
- 실시간 task가 즉시 수행되도록 interrupt latency를 최소화해야 됨
- hard real time system 에서는 단순히 최소화가 아닌, 엄격하게 충족해야 됨
- latency에 영향 ← kernel data가 update 되는 동안 interrupt disable되는 시간
2. Dispatch latency
- dispatcher가 한 process를 멈추고 다른 process를 시작하기 위해 필요한 시간
- CPU에 즉시 접근해야 하는 실시간 task는 실시간 OS는 dispatch latency도 최소화 해야 함
- dispatch latency를 최소화하는 가장 효과적인 방법 → 선점형 커널 사용
- hard 실시간 시스템인 경우 dispatch latency는 몇 마이크로 초 이내
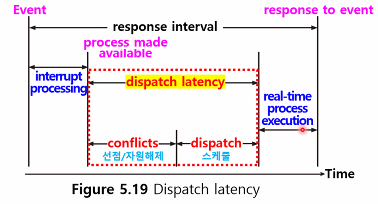
- conflict phase : Preemption & Release
- dispatch phase : 우선 순위가 높은 process에 가용한 CPU에 스케줄
5.6.2 Priority-based Scheduling
- 중요도에 따라 우선순위를 부여하고, 우선순위에 따라서 자원을 선점
- 높은 우선순위의 프로세스가 실행될 수 있다면, 현재 CPU에서 실행중인 프로세스가 선점됨
- Hard real-time system → 실시간 task가 deadline 요구 내에 서비스되어야 함을 보장
Real-time Process의 특성
- 주기적이다 → 일정 간격으로 CPU를 요구
fixed processing time : t
deadline : d
period : p
0 ≤ t ≤ d ≤ p rate of periodic task = 1/p
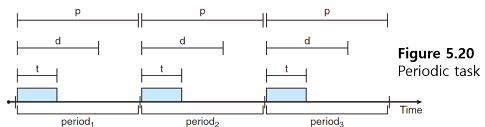
- 프로세스는 스케줄러에게 자신의 deadline 요구사항을 알려야 함; unusual 상황
- admission-control 알고리즘 사용
- process가 시간 내에 완료 가능함을 보장할 수 있다면 허락함
- 보장할 수 없다면 요청이 불가능한 것으로 거절함
5.6.3 Rate-Monotonic (RM) Scheduling
- static prioirty policy with preemption
- period의 역으로 priority 할당 (주기 down, 우선순위 up)
- CPU를 잠깐씩 자주 요구하면 높은 우선순위

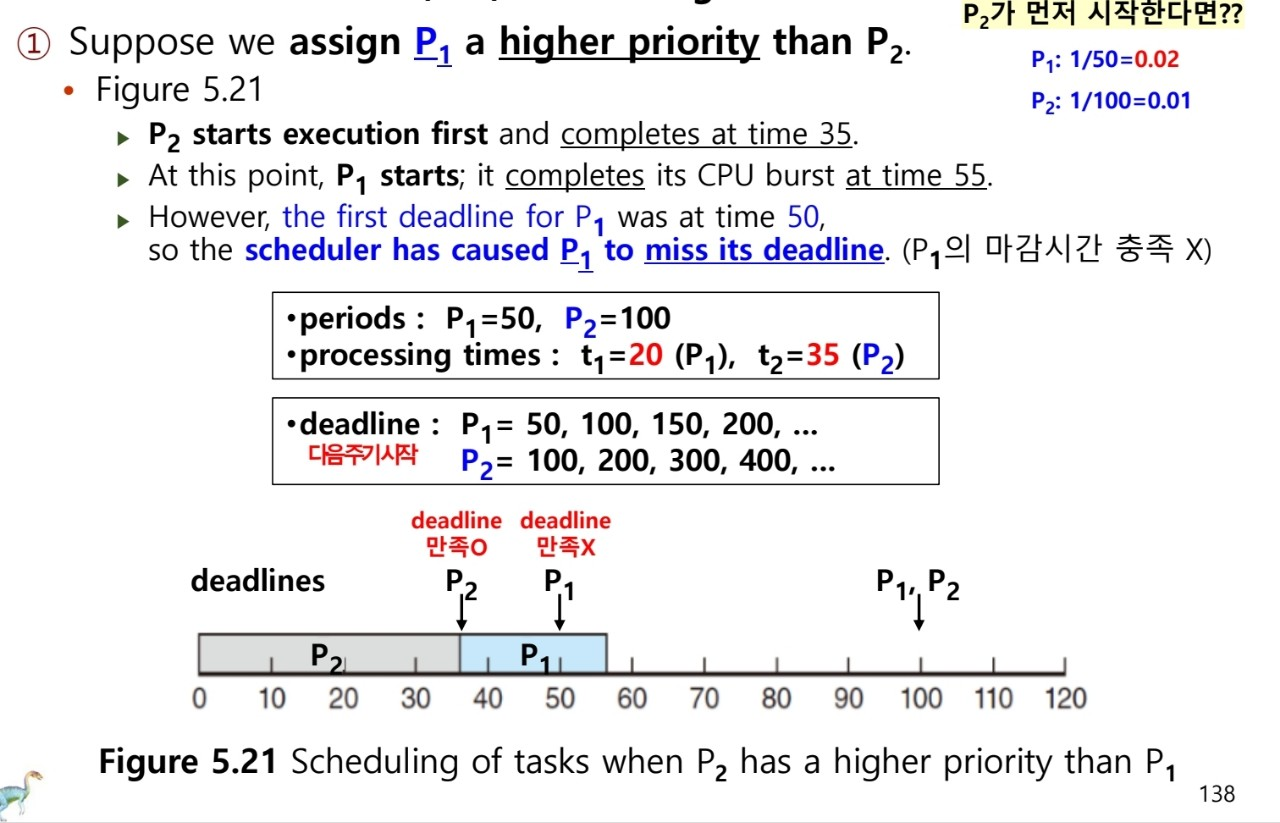

⇒ RM은 optimal하다 : 어떤 프로세스 집합을 RM 알고리즘으로 스케줄 할 수 없다면, static priority를 할당하는 어떤 다른 알고리즘으로도 스케줄 불가능

- CPU 이용률의 한계로 CPU 자원을 항상 최대화하는 것은 불가능
- worst-case CPU utilization for scheduling N processes : N(2^1(1/N) -1)
5.6.4 Earliest -Deadline-First (EFD) Scheduling
- Deadline에 따라 동적으로 스케줄 (deadline이 가장 앞에 있는 것 부터)
- Deadline에 따라 Preemption이 가능하다
- process는 실행 가능한 상태가 되면, 시스템에 deadline을 알려야 하는데, 우선 순위가 새로 실행가능한 process의 deadline을 반영해서 조정된다.
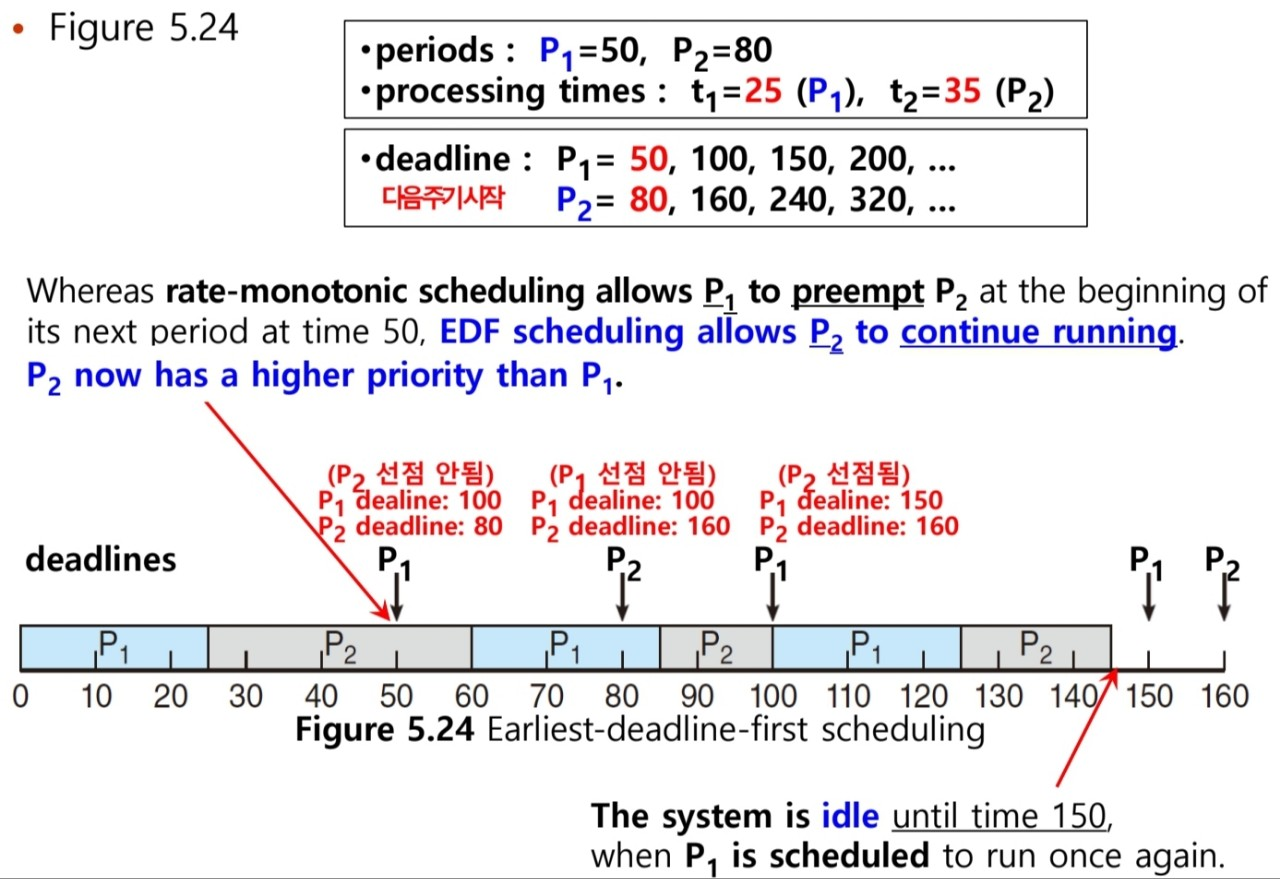
- EDF 스케줄링은 프로세스가 주기적이거나, CPU burst time이 상수일 필요가 없음
- ⇒ 단지 실행 가능할 때, 스케줄러에게 deadline을 알리기만 하면 됨
- 이론적으로, 각 프로세스의 deadline 요구를 만족시키고, CPU 이용률이 100%임
- 실제 process 간 context switching, interrupt 처리로 인해 100% CPU 이용률은 불가능
5.6.5 Proportional Share Scheduling
- 모든 Application들이 총 시간 “T”를 할당 받아 실행된다.
- 하나의 application이 N 시간 몫을 할당받으면, “N/T” 만큼의 시간을 갖는다.
- 스케줄러는 Application의 시간(몫) 할당량을 보장하기 위해 admission-control policy와 함께 동작한다. (보장할 수 있을 때만 accept/admit 하여 스케줄함)
- 가용한 충분한 몫이 있을 때, 특정한 몫을 요구하는 clinet를 허용한다.
- ex) T = 100일 때B = 15 shares 할당 → 15% CPU Time⇒ 총 100 shares 중 85 shares를 사용한다. 이때 새로운 process인 D가 30 shares를 요구하면, 남은 shares보다 크기 때문에 admission controller가 해당 요구를 거절한다!
- C = 20 shares 할당 → 20% CPU Time
- A = 50 shares 할당 → 50% CPU Time
5.8 Algorithm Evaluation
5.8.1 Deterministic Modeling
- 분석적 평가에 쓰이는 모델 중 하나
- 미리 정의된 특정 작업 부하를 이용하여 각 알고리즘의 성능을 정의한다.
Example


'Computer Science > Operating System' 카테고리의 다른 글
| [운영체제] 공룡책🦖 ch07. Synchronization Examples (0) | 2022.12.01 |
|---|---|
| [운영체제] 공룡책🦖 ch06. Synchronization Tools (0) | 2022.11.23 |
| [운영체제] 공룡책🦖 ch04. Threads & Concurrency (0) | 2022.10.24 |
| [운영체제] 공룡책🦖 ch03. Processes (0) | 2022.10.08 |
| [운영체제] 공룡책🦖 ch02. Operating-System Structures (0) | 2022.10.08 |
- 목차
- 5.1 Basic Concepts
- Mulitiprogramming을 위해서
- CPU-I/O Burst Cycle
- 5.1.2 CPU Scheduler
- 5.1.3 Preemptive(선점) and Nonpreemptive(비선점) Scheduling
- 5.1.4 Dispatcher
- 5.2 Scheduling Criteria
- Scheduling Criteria (CPU 스케줄링 비교 기준)
- 5.3 Scheduling Algorithms
- 5.3.1 First-Come, First-Server Scheduling (FCFS)
- Gantt chart : 특정 스케줄 기법을 도시한 막대 차트
- Convoy effect (호위 효과)
- 5.3.2 Shortest-Job-First Scheduling (SJF)
- approximate SJF scheduling
- 5.3.3 Round-Robin Scheduling (RR) : FCFS + Preemption
- 5.3.4 Priority Scheduling
- 5.3.5 Multilevel Queue Scheduling
- 5.3.6 Multilevel Feedback Queue Scheduling
- 5.4 Thread Scheduling
- 5.4.1 Contention Scope
- 5.4.2 Pthread Scheduling
- 5.5 Multi-Processor Scheduling
- 5.5.1 Approaches to Multiple-Processor Schduling
- 5.5.2 Multicore Processors
- 5.5.3 Load balancing (부하 균등)
- 5.5.4 Processor Affinity
- 5.5.5 Heterogeneous Multiprocessing
- 5.6 Real-Time CPU Schduling
- 5.6.1 Minimizing Latency
- 5.6.2 Priority-based Scheduling
- Real-time Process의 특성
- 5.6.3 Rate-Monotonic (RM) Scheduling
- 5.6.4 Earliest -Deadline-First (EFD) Scheduling
- 5.6.5 Proportional Share Scheduling
- 5.8 Algorithm Evaluation
- 5.8.1 Deterministic Modeling