Computer Science/Database
[데이터베이스] Chapter 13. Data Storage Structures
great_park
2022. 10. 8. 20:12
반응형
Reference
1. Database System Concepts-Abraham Silberschatz, Henry Korth, S. Sudarshan
2. Database System class by Professor Yon Dohn Chung, Department of Computer Science and Engineering, Korea University
중요한 내용 위주로 요약 & 정리하였습니다.
13.2 File Organization
file : file system의 저장 단위로, record들의 집합이다.
- database는 files의 collection이다.
- 각 file은 record의 sequence이다. (여러 relation)
Fixed-Length Record - 비현실적
각 record의 size가 n으로 고정되었다면,
- 접근은 쉽지만, record에 넣을 수 있는 data가 제한적이다.
- 삭제 시, record를 빈 칸(free record)으로 옮기는 대신에, free record끼리 이어서 관리

Variable-Length Record
다양한 record type을 수용하기 위해서 길이를 고정하지 않은 record를 사용한다.
- 고정된 길이의 (offset, length)로 나타낸다.
- sequential scan할 필요 없이 바로 접근할 수 있다.

Slotted Page Structure

Slooted page header에는
- record entried의 개수
- block 내 free space의 끝 위치
- 각 record의 위치와 길이
그 외,
- record 사이에는 빈 공간이 있어서는 안되며, header도 같이 update됩니다.
- pointer는 record를 직접 가리키는게 아니라 header에 있는 record를 가리킨다.
Storing Large Objects
- DBMS 밖인 file system에 보관
- 조각 내서 보관
13.3 Organization of Records in Files
- Heap
- Sequential
- multitable clustering file organization
- B+ tree file organization
- Hashing
1. Heap File Organization
- file 내 free space를 찾기 위해서 Free-space map을 관리한다.
2. Sequential File Organization
- search-key를 기준으로 file 내 record를 정렬한다.
3. Multitable Clustering File Organization
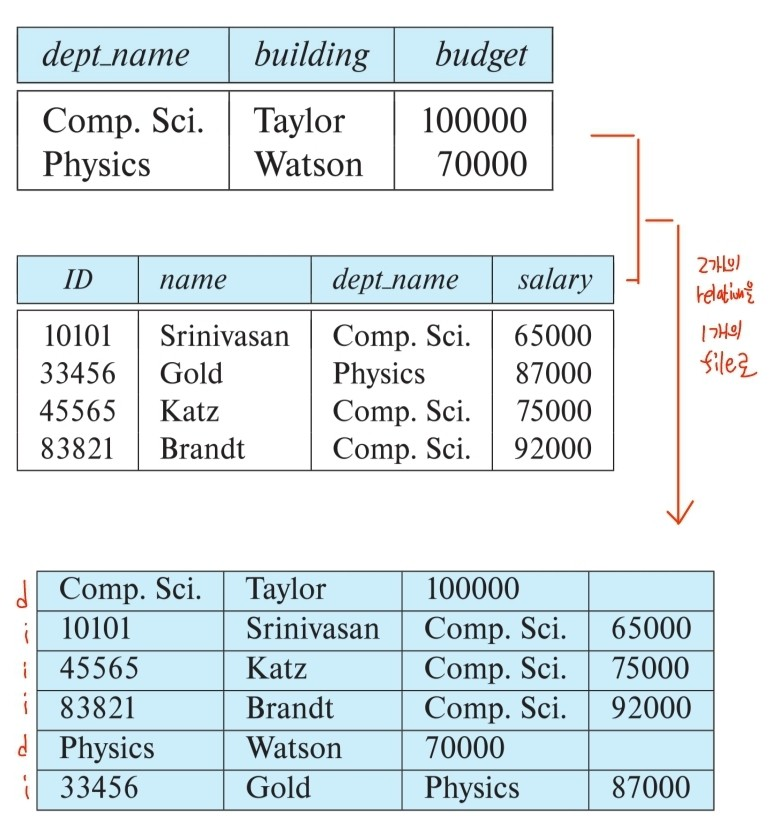
- 두 relation을 포함하는 query에서는 좋은 성능을 보여주나, 오직 하나의 relation에 대한 query의 성능은 떨어진다.
4. Partitioning
- Table partitioning : table을 누락없고, 겹칩없이 나누어 보관한다. (sharding)
13.4 Data Dictionary Storage (System catalog)
- metadata를 저장
- relation에 대한 정보
- 계정 정보
- 통계 자료
- Physical file organization information
- index 관련 정보
13.5 Database Buffer
Storage Access
- Block 단위로 storage 할당, data 전송
- Buffer : main memory 내 공간, disk block의 복사본을 저장
- Buffer manager : buffer space를 관리하는 subsystem

Buffer-Replacement Policies
- least recently used (LRU strategy) : 가장 마지막에 사용한 건 버퍼에서 제거 (heuristic)
LRU p.605
Most operating systems use a least recently used (LRU) scheme, in which the block that was referenced least recently is written back to disk and is removed from the buffer.
LRU의 worst case는?
⇒ buffer에서 버리자마자 다시 찾는 경우
⇒ nested loop일 때 worst case이다.
⇒ loop의 마지막에서 첫 줄을 버리고, 다음 loop 들어가면서 다시 첫 줄을 읽어야 됨
- DBMS가 access 패턴을 미리 예측하여 buffer에 갖다 놓음, replacement 조절
- Toss-ommediate strategy : block내 마지막 tuple을 읽자마자 block이 차지하는 공간을 비움
- Most recently userd (MRU strategy) : 가장 최근에 사용한 건 버퍼에서 제거
- 통계 정보를 담은 data dictionary block을 main memory buffer에서 관리 - 특정 relation 요청에 대한 통계
- Pinned block : disk에 wirte back하지 못하도록 제한하는 block
⇒ reading/writing이 진행되고 있는 block
- Shared and exclusive locks on buffer
Optimizations of Disk Block Access
- Nonvolatile write buffers : 별도의 하드웨어(NV-RAM), disk 대신 여기로 빠른 접근이 가능하도록 함. disk에 한 번에 반영하여 효율적
- Log disk : log용 disk로 순서대로 쌓인다. append만 됨
- Journaling file systems : NV-RAM or log disk의 순서대로 data를 write
13.6 Column-Oriented Storage
- columnar representation
- relation을 attribute별로 찢어서 보관
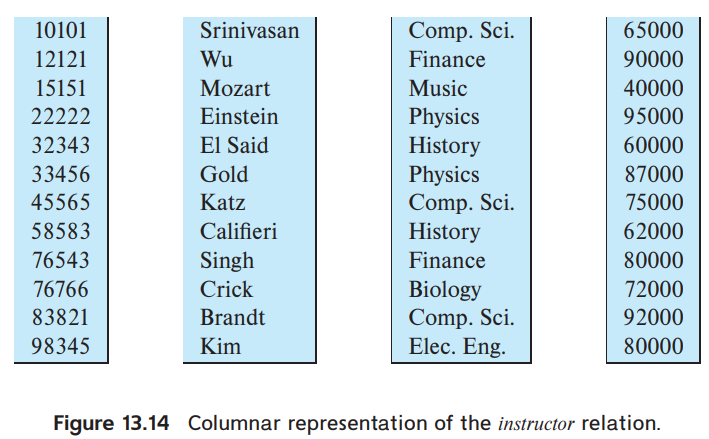
장점
- 특정 attirbute를 접근할 때 좋다.
- CPU cache 성능 개선
- 압축하기 좋다
- vector processing
단점
- tuple 재구성 비용이 비쌈
- tuple 삭제, 수정이 힘들다
- 압축 해제가 힘들다
반응형