[데이터베이스] Chapter 12. Physical Storage Systems - Disk mechanism, RAID Level
Reference
1. Database System Concepts-Abraham Silberschatz, Henry Korth, S. Sudarshan
2. Database System class by Professor Yon Dohn Chung, Department of Computer Science and Engineering, Korea University
중요한 내용 위주로 요약 & 정리하였습니다.
뒤에서 나올 indexing, query processing and optimization 등을 이해하려면 storage 구조에 대해서 학습해야 합니다.
12.1 Overview of Physical Storage Media
- volatile storage : 휘발성, 전원 끄면 사라짐
- non-volatile storage : 비휘발성, 전원 꺼도 data가 살아있음
Storage Hierarchy

- primary storage : Fastest media, 휘발성 (cache, main memory)
- secondary storage : moderately fast, 비 휘발성, on-line (flash memory, disk)
- tertiary storage : slow, 비 휘발성, 보관 용도, off-line
Storage Interfaces
- Disk interface : SATA, SAS, NVMe
- disk는 보통 computer system과 직접 연결
- SAN, NAS
12.3 Magenetic Hard Disk Mechanism

- Read-write head : disk를 읽는 부분
- track : platter가 나뉘는 원형의 단위
- sector : track을 나누는 단위
- cylinder : platter의 집합
- Disk controller : computer system과 disk drive hardware간 interface
⇒ sector에 대한 read, write 의 빠른 접근을 도와줌, checksum 진행하여 각 sector가 제대로 읽히는 지 검사, 망가진 track은 다른 곳으로 옮기고 bad sector는 remapping
Performance Measures of Disks
Access time : data 접근 시간, read, write 요청이 들어오고 data transfer가 이뤄지기 전까지의 시간
- seek time : track 찾기, head의 직선 운동
- rotational latency : head 밑에 원하는 sector가 오기까지의 지연 시간, 회전 운동
Data-transfer rate : data가 disk에서 가져오거나 저장하는 시간
Mean time to failure (MTTF) : 실패 없이 연속적으로 disk가 동작하는 평균 시간
- 클수록 좋다.
- 수명이 길어질수록 짧아진다.
DIsk block : sector의 묶음, storage 할당에 logical unit , 512 byte
Seqeuntail access pattern : 연속적인 block에 대한 요청 → 첫 block을 seek
Random access pattern : 랜덤하게 block 요청 → 각 access마다 seek
I/O operantions per sencond (IOPS) : 임의의 random access를 얼마나 빨리 처리하는 지
12.4 Flash memory
NAND Flash
- page 단위
- read, wirte, erase(매우 느림)
- overwrite 개념이 없다.
- 한 곳에 쓸 수 있는 횟수 제한
Solid state disk (SSD)
- block-oriemted disk interface 사용하지만 data 저장은 multiple flash storage 사용
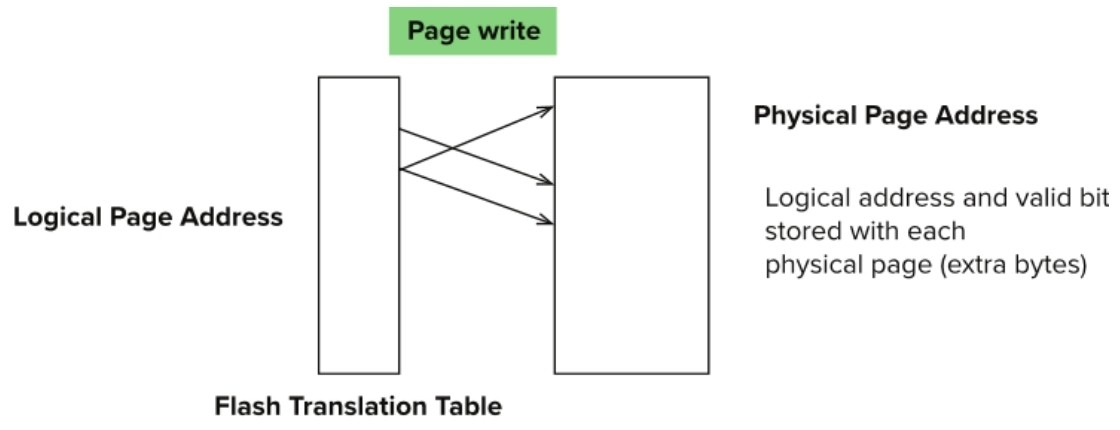
Erase block
- Remapping → logical page 주소와 physical page 주소
- Flash translation table tracks mapping → flash translation layer에 따라 remapping
12.5 RAID
RAID : Redindant Arrays of Independent Disks
RAID는 뜻 그대로 여러 개의 disk를 묶어서 하나의 disk처럼 사용하는 기술입니다.
RAID 사용 이유 ⇒ Redundancy, Parallelism
Improvement of Reliability via Redundancy
- 데이터를 중복으로 저장하여 안정성 향상 → Mirroring(shadowing)
- disk가 여러 개니 MTTF가 작다.
Improvemnt in Performance via Parallelism
- multiple small access를 load balancing → throughtput 증가 (단일 시간 당 요청 처리)
- 다량의 disk를 병렬적으로 사용하여 high capacity, high speed → 응답 시간 감소
- Bit-level striping
- Block-level striping : block 단위로 나누기
RAID Levels
RAID level에는 0부터 6까지 있지만, 실제로 사용되는 level은 0, 1, 5, 6 입니다.
Parity blocks
- disk 장애 시 데이터를 재 구축하는데 사용할 수 있는 사전에 계산된 값
- ex) disk의 4개의 block 중 3개에 data 넣고 1개는 parity 영역
- mirring에 비해 작은 용량으로 disk가 망가질 때 repair 가능
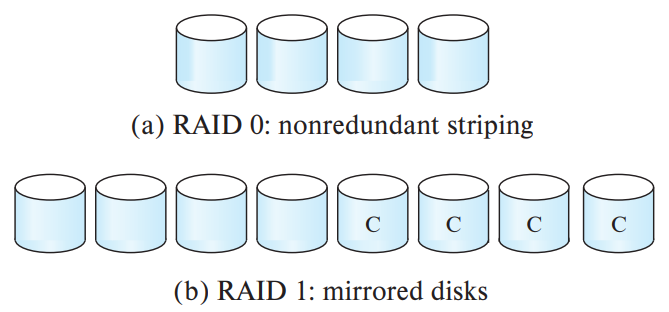
RAID 0
- RAID 구성하는 모든 disk에 데이터를 분할하여 저장
- block striping
- non-redundant
- N개 → 성능 N배 , 안정성 1/N배 : 성능과 용량은 최대로, 안정성은 극악
RAID 1 (1+ 0)
- 동일한 data를 N개로 복제하여 각 disk에 저장
- Mirroed disk with block striping
- redundant
- write 성능 1/N배, read 성능 N배, 안정성 N배
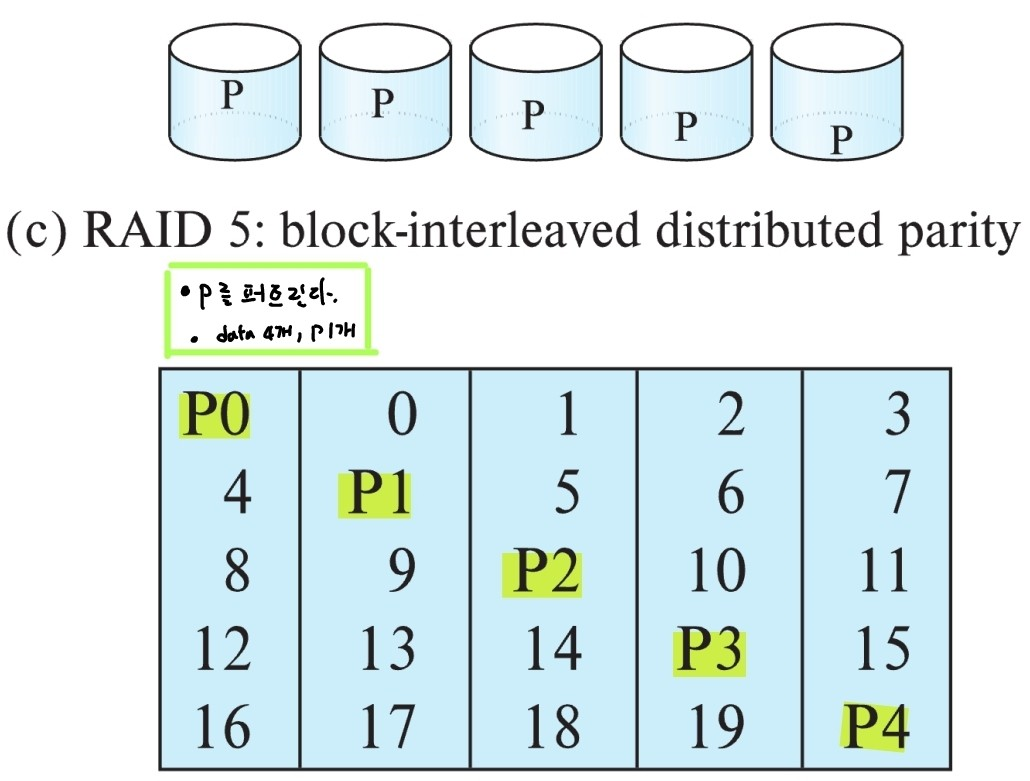
RAID 5
- Block 단위로 striping 후 error 감지를 위해서 parity 1개를 저장
- Block-Interleaved Distributed Parity
- Parity는 disk를 고정하지 않고 매번 다른 disk에 저장한다.
- 용량, 성능 N-1배 증가
- RAID 0에서 성능, 용량을 조금 줄이는 대신 안정성을 높인 RAID level
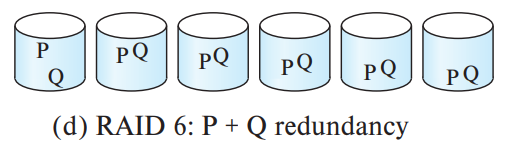
RAID 6
- Block 단위로 striping 후 error 감지를 위해 parity 2개를 disk에 저장
- Block-Interleaved Distributed Parity
- Parity는 disk를 고정하지 않고 매번 다른 disk에 저장한다.
- 용량, 성능 N-2배 증가
- RAID 5에서 성능, 용량을 조금 줄이는 대신 안정성을 높인 RAID Level
Choice of RAID Level
- cost
- performance - I/O operation per second
- performance during failure and rebuild
Hardware Issues
Software RAID : hardware 도움 없이 오직 software만으로 RAID를 구현하는 것
Hardware RAID : NV-RAM (cache) 사용하여 write 기록을 저장
주의점 : disk와 mirroring disk간 차이가 발생할 수 있다. → recovery 필요
- 요청을 받을 때, 앞 단에 NV-RAM을 거치도록 만든다.
- NV-RAM이 효율적인 recovery 도움 → corrupted block을 효율적으로 감지
Latent failures : 자석이 약해지면 시간이 지나면서 data가 사라짐
Data scrubbing : latent failure을 미리 감별해서 복구
Hot swapping :
⇒ 많은 hardware RAID system이 단 하나의 failure가 일어나지 않도록 보장해줌
Optimization of Disk-Block Access
- Buffering : in-memory buffer에 disk block을 caching
- Read-ahead : 요청 전에 미리 memory에 불러두기 (prefetching)
- Disk-arm-scheduling : disk controller가 가는 길에 있는 요청을 함께 처리